CUDA et Programmation Générale sur GPU
Architecture Technique
Le hardware
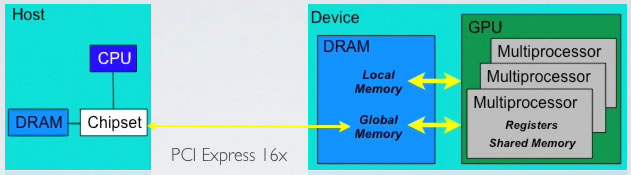
D'un coté, la carte mère, le CPU et la RAM (DRAM). De l'autre, la carte graphique avec de la mémoire globale (DRAM GDDR) qui est utilisée par le GPU.
Ce dernier est composé de multiprocesseurs qui exécutent chacun des grilles de blocs de threads. Chaque multiprocesseur dispose d'un certain nombre de registres, et d'un cache servant à stocker la mémoire partagée aux blocs de threads.
Le GPU
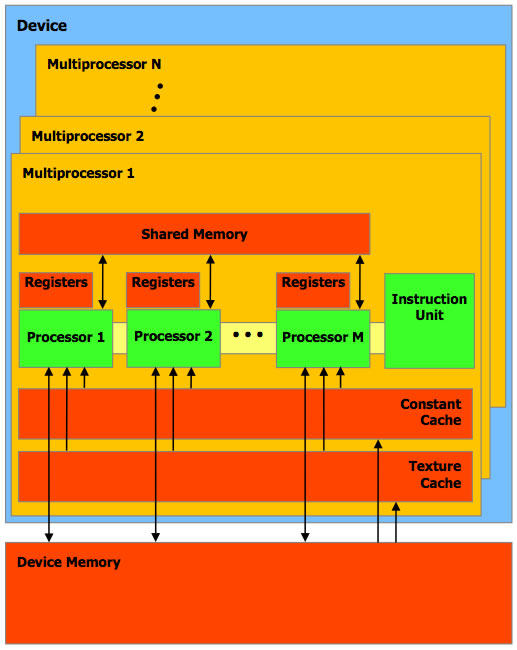 |
Au sein d'un GPU, chaque multiprocesseur est composé de plusieurs processeurs, et d'un unité d'instructions qui contient les instructions des kernels. On note que les banques de registres sont intégrées aux processeurs. Ainsi, si on utilise un grand nombre de registres dans nos threads, le nombre de ces threads exécutés en même temps sera adapté à la capacité des processeurs, d'où une occupation totale du GPU potentiellement non optimale. Attention à l'optimisation ! Le même principe s'applique pour la mémoire partagée, qui est en quantité limitée dans chaque multiprocesseur. On note également la présence de caches pour les constantes (déclarées avec le mot clé __constant__ dans le code) et pour des textures. Peu de détails sur performances et l'utilisation optimale de ces caches sont cependant disponibles. Enfin, une notion importante est la notion de Warps. En effet, lors de l'exécution, le multiprocesseur planifie l'exécution des threads en les regrouppant en ensembles de 32 Threads maximum appelés Warps (indépendemment de l'organisation des threads en blocs). Quelques chiffres, sur une GeForce 8800GTX :
|