CUDA et Programmation Générale sur GPU
GPUs et CPUs
Le calcul sur Processeur Graphique
La tache principale d'un processeur graphique (GPU) est de passer d'une liste d'objets ayant des coordonnées spatiales (décomposés en triangles) à une image en deux dimensions à afficher sur le moniteur du joueur, et ce plusieurs fois par seconde (au moins 25 fois pour que l'animation paraisse fluide).
Il doit donc déterminer l'aspect visuel de chaque triangle en fonction du point de vue de la "caméra", comme illustré sur l'image suivante :

Pour chaque triangle, sa position est absolue et ne dépends pas de celles d'autres triangles, et le volume d'information est relativement faible. Également, la précision du calcul du rendu d'un triangle n'est pas primordiale, car l'erreur peut passer inaperçu (noyée dans la quantité de triangles et de frames produites, et dans l'arrondi dû à la perspective du champ).
Ainsi, l'architecture des GPU s'est adaptée en conséquence pour maximiser le nombre de triangles traités en un temps donné, en parallélisant au maximum les unités de calcul (qui disposent de peu de cache), en minimisant les structures de contrôle et en optimisant le jeu d'instructions.
Architecture des GPU et CPU
Cela s'illustre lorsqu'on regarde de plus près la répartition des transistors entre un GPU et un CPU :
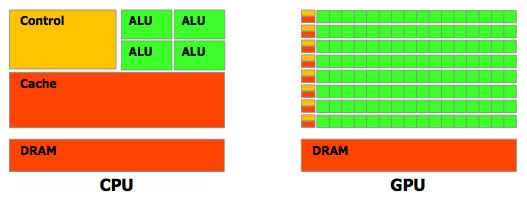
En effet, un CPU dispose de peu d'unités de calcul (ici 4 ALU), mais d'un cache volumineux (plusieurs Mégaoctets) et une unité de contrôle importante. Cela est dû à sa mission : gérer plusieurs tâches très différentes en parallèle qui nécessitent beaucoup de données. Ainsi, les données sont stockés en cache pour accélérer leur accès, et l'unité de contrôle va optimiser le flux d'instructions pour maximiser l'occupation des unités de calcul et optimiser la gestion du cache.
À l'inverse, un GPU dispose d'un nombre important d'unités de calcul (plusieurs dizaines) qui disposent de peu de cache (quelques Kilooctets) et de faibles unités de contrôle. Cela lui permet de calculer de façon massivement parallèle le rendu de ces petits éléments indépendants, tout en ayant un débit important de données traitées.
Performances
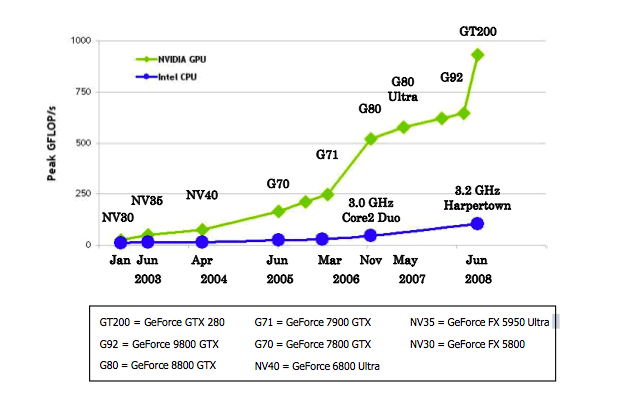
Dans un cas de figure idéal en faveur du GPU (calculs massivement paralélisables sur des nombres flottants en simple précision sans contraintes mémoire), on remarque que le GPU dispose d'un avantage non négligeable sur le CPU. Il faut toutefois garder en mémoire que ces performances ne se traduisent en gains identiques pour des applications concrètes : de nombreux goulots d'étranglements peuvent apparaitrent, et une bonne optimisation est nécessaire pour tirer parti de cette capacité de calcul.
Également, la bande passante de la mémoire embarquée sur la carte graphique est très importante :
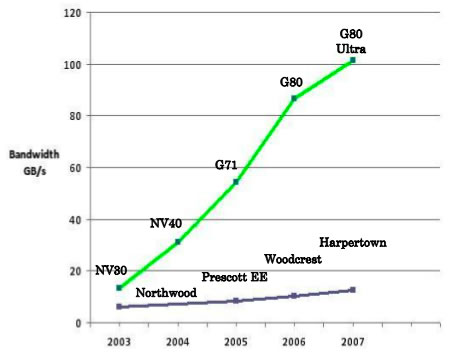
Ces chiffres (fournis par nVIDIA) sont encore à prendre avec des pincettes : si la bande passante de la mémoire est effectivement importante, la latence pour y accéder l'est également (mais optimisable). De plus, le rapatriement de données depuis la RAM de l'ordinateur à la mémoire graphique subit la contrainte du bus de la carte graphique (désormais PCI-Express 2.0), qui atteint 8Go/s (dans le meilleur des cas, souvent largement moindre, cf. la démonstration).
... en conclusion
Ainsi, le calcul sur carte graphique promet de gros gains, mais il faut que les calculs que l'on souhaite y faire tiennent compte des contraintes techniques (cf. la prochaine partie) pour que les gains soient substantiels.