CUDA et Programmation Générale sur GPU
La mémoire
Généralités
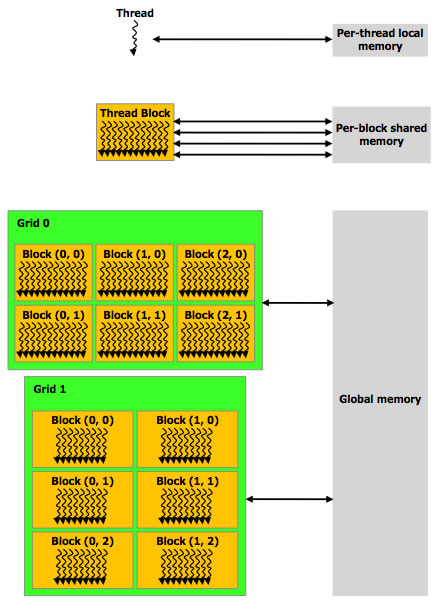 |
La programmation sur GPU avec CUDA propose 3 principaux types de mémoire :
A noter également que d'autres de zones mémoire sont disponibles (cache pour les variables statiques, cache de textures), mais sont basés physiquement sur les types de mémoire présentés précédemment. Il y a relativement peu d'informations disponibles sur ces caches, le mieux est de tester leur performances en fonction du contexte d'utilisation. |
La mémoire partagée

La mémoire partagée est un espace mémoire commun à un bloc, organisé en banques de 32bit.
L'accès à cette mémoire est instantané (comme pour les registres), sauf dans le cas d'un conflit d'accès entre deux threads d'un même bloc.
Pour allouer une variable dans l'espace mémoire partagé, il faut précéder la déclaration de la variable du mot clé __shared__.
Exemple : __shared__ tab[TAB_SIZE];
Lors de l'appel du kernel, il ne faut pas oublier de préciser la taille de la mémoire partagée qui sera réservée pour chaque bloc dans les paramètres de lancement du kernel (<<<...>>>), sous peine de générer une erreur à l'exécution (cf. les kernels CUDA).
Il est possible de synchroniser les threads d'un bloc avec la fonction __syncthreads(). Cette fonction peut être particulièrement utile lorsque l'on souhaite attendre que tous les threads du bloc aient, à la suite de calculs, fini d'inscrire leurs résultats dans la mémoire partagée. On peut alors recopier les résultats dans la mémoire globale en étant sûr que les valeurs de la mémoire partagée sont bonnes.
La mémoire globale
La mémoire globale correspond à la mémoire vidéo de la carte graphique. Elle propose beaucoup plus d'espace que la mémoire partagée (de 512Mo à plusieurs Go, contre quelques dizaines de Ko), mais l'accès est beaucoup plus lent (plusieurs centaines de cycles contre un accès quasi-instantané).
L'allocation d'espace en mémoire globale se fait avec l'utilisation de fonction telles que cudaMalloc(), cudaFree(), qui sont les équivalents CUDA des fonctions traditionnelles du C de gestion de la mémoire.
Il est également possible de procéder à des copies mémoire entre la mémoire centrale (RAM) et la mémoire globale en utilisant les fonctions cudaMemcpyHostToDevice(), cudaMemcpyDeviceToHost() et cudaMemcpyDeviceToDevice(). Le choix de la méthode dépends du sens de copie que l'on souhaite. De plus, il existe des variantes asynchrones de ces fonctions en utilisant cudaMemcpyAsync().
Il ne faut cependant pas oublier que les copies de données entre la RAM et la mémoire globale passent par le bus PCI-Express, dont la bande passante est limitée (8Go/s en théorie pour un bus PCIe 2.0 16x, entre 2 et 4Go/s en pratique).