CUDA et Programmation Générale sur GPU
Démonstration : Le calcul de hash MD5
Contexte
Une version du code de calcul de hash MD5 de la RSA est disponible à cette adresse : http://majuric.org/software/cudamd5/
Après avoir adapté ce code pour la version 2.0 du SDK pour Mac OS X, les tests suivant ont été fait :
- benchmark du code cudamd5 sur le GPU en mode recherche (les hash ne sont pas rappatriés du GPU à la mémoire centrale)
- benchmark du code cudamd5 sur le GPU
- benchmark du code cudamd5 sur le CPU
- benchmark du code MDCrack sur le CPU (code hautement optimisé)
Les tests ont été réalisés sur la machine suivante :
- Mac Pro '08
- 1 x Intel Xeon Quad 2.8GHz
- 12 Go de RAM
- Geforce 8800GT (512Mo GDDR2)
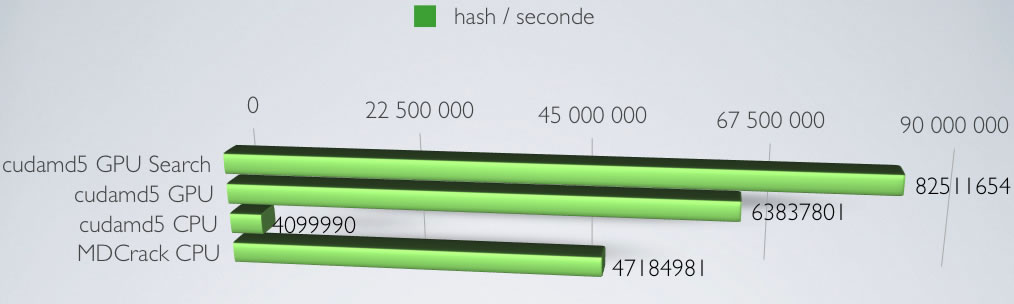
On peu remarquer que le calcul sur GPU est bien plus rapide que sur CPU, alors que le code n'est pas optimisé du tout (on voit la différence sur CPU entre cudamd5 est le code de MDCrack qui lui est optimisé).
Ainsi, en optimisant le code, nous pourrions tirer plus de performances de la part du GPU.
En effet, en ajoutant l'option de compilation "--ptxas-options=-v", nous pouvons constater que chaque thread utilise 23 registres et 32 octets de mémoire partagée. Ainsi, la feuille excel de GPU Occupancy Calculator nous indique que le GPU fonctionne à 42% de sa capacité, et que le goulot d'étranglement se situe au niveau du nombre de registres utilisés qui est beaucoup trop important. Une piste d'optimisation serait de réduire l'utilisation de ces registres au profit de la mémoire partagée qui là n'est pas utilisée du tout.