Choisir sa base de données Relationnelle
Assurer la disponibilité des données
Contexte
La problématique posée ici est de savoir si la base de données que l'on doit mettre en place doit être disponible à tout moment durant son temps d'exploitation
ou si le client pour lequel on met cette base en place peut supporter un arrêt momentané.
On distingue trois types de disponibilité :
- Disponibilité 100 %
- Disponibilité Inférieur à 100 % sans perte de données
- Disponibilité Inférieur à 100 % avec perte de données
Disponibilité 100 %
Dans le cas d'une Disponibilité 100 %, le client souhaite que la base de donnée soit accessible à tous moment durant son temps d'exploitation. Cela implique de mettre en place une architecture de type "cluster" composée d'au moins 2 serveurs de base de données qui vont travailler ensemble afin de répondre aux demandes. Dans le cas où l'un des serveurs serait indisponible (maintenance, crash ...) ce sont les autres serveur composant le cluster qui prendrons le relais.
Chaque système de gestion de base de donnée relationnelle implémente un type de cluster:
Le cluster partagé
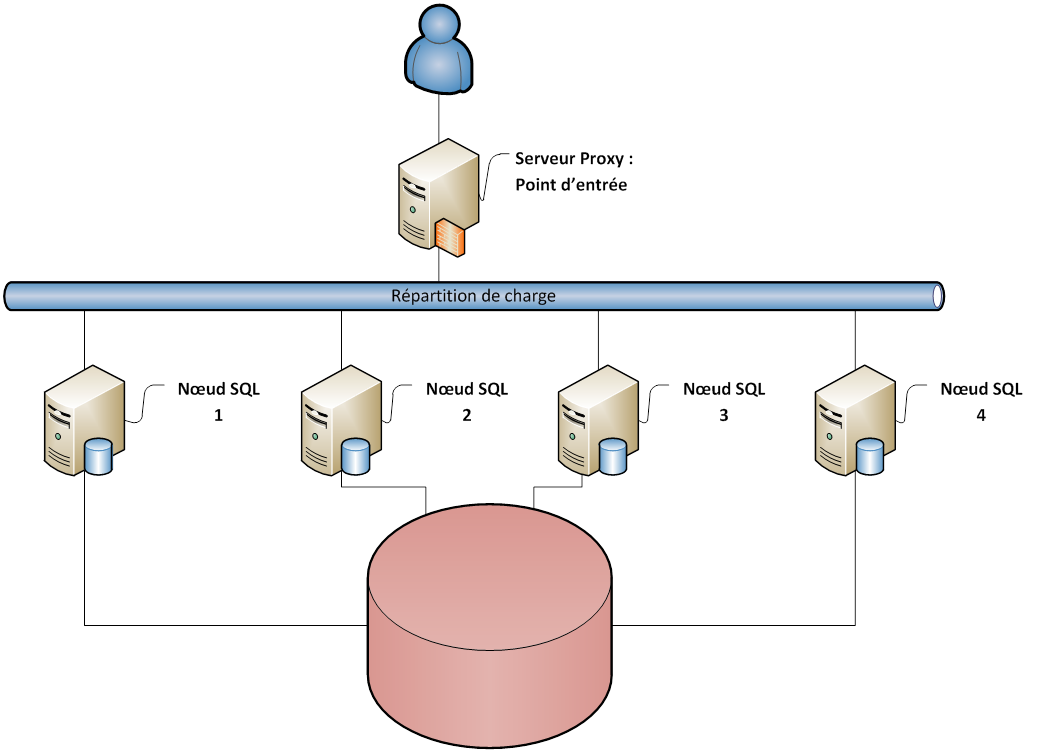
Dans ce type de cluster, tous les serveurs de base de données (Noud SQL) attaquent le même espace de stockage de données. Pour accéder à la base, les utilisateurs passent par un serveur SQL "proxy" qui joue le rôle du répartiteur de charge. Ce répartiteur de charge à pour tâche de répartir les demandes entres les différents serveurs du cluster et de gérer les accès concurrents à l'espace de stockage.
Le cluster distribué
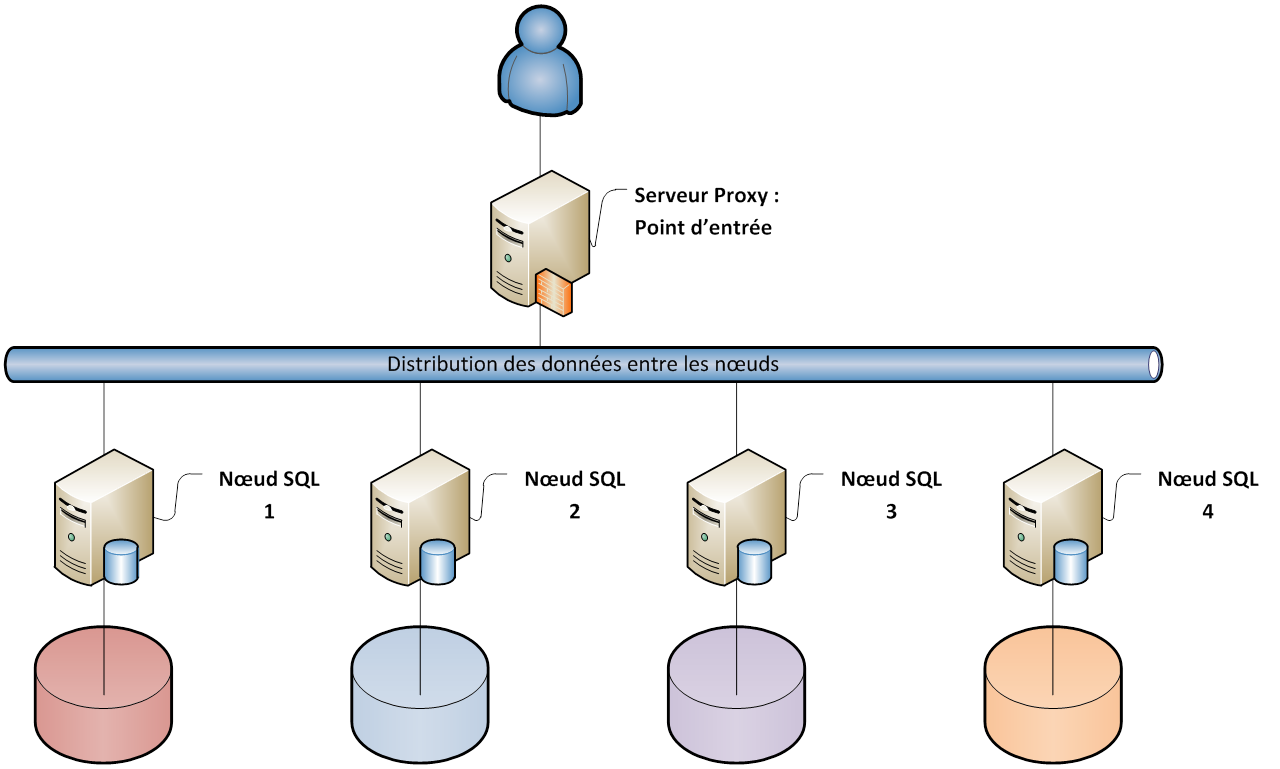
Dans ce type de cluster, chaque serveur du cluster possède son propre espace de stockage sur lequel est stocké une partie de la base de donnée. C'est le serveur "proxy" qui possède la cartographie exacte des données stockés sur les différents serveur et qui est en charge de les rassembler lors des demandes du client.
Le cluster répliqué
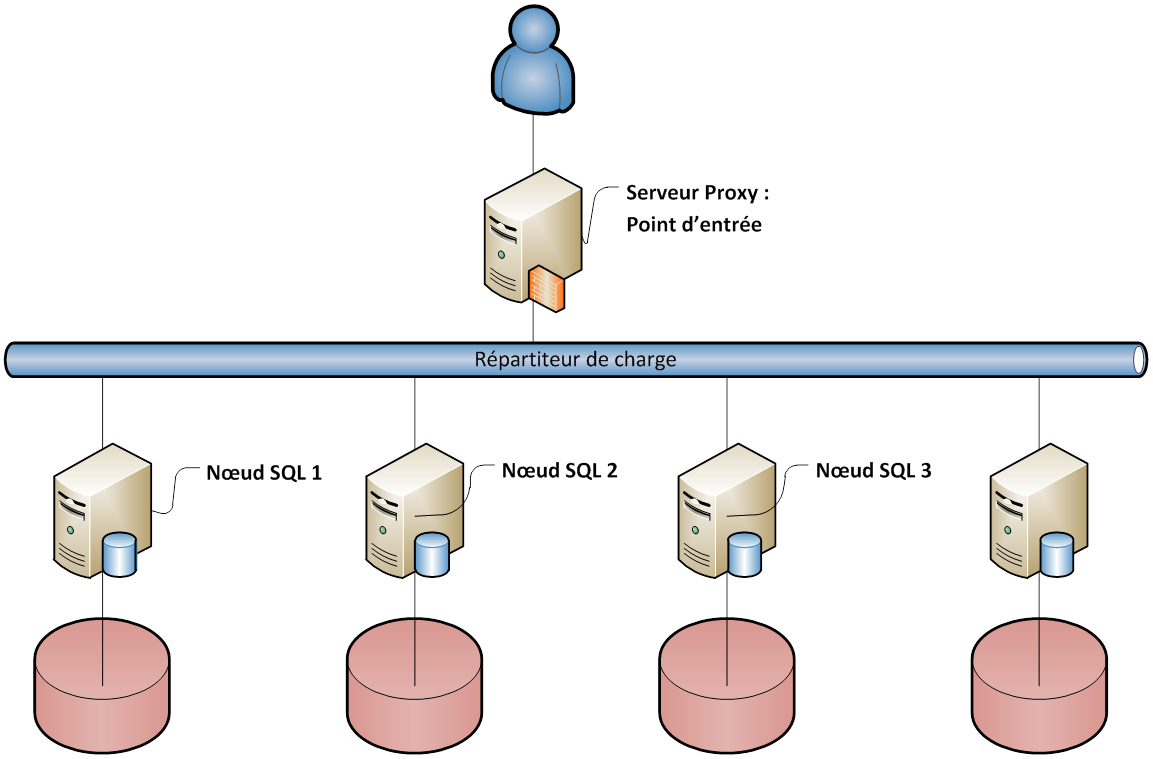
Dans ce type de cluster, chaque serveur du cluster possède son propre espace de stockage sur lequel est stocké une copie de la base de donnée. Le serveur SQL "proxy" joue le rôle du répartiteur de charge pour répondre aux demandes du client.
Disponibilité Inférieur à 100 %
Lorsque que le client indique qu'il peut supporter des coupures d'accès à la base de données, on se retrouve dans le cas d'une disponibilité inférieur à 100 %. Si la coupure supportée peut être
importante (en général plus d'une heure) il est possible de se reposer uniquement sur les sauvegardes. Dans le cas contraire il faut un système de réplication de la base de données.
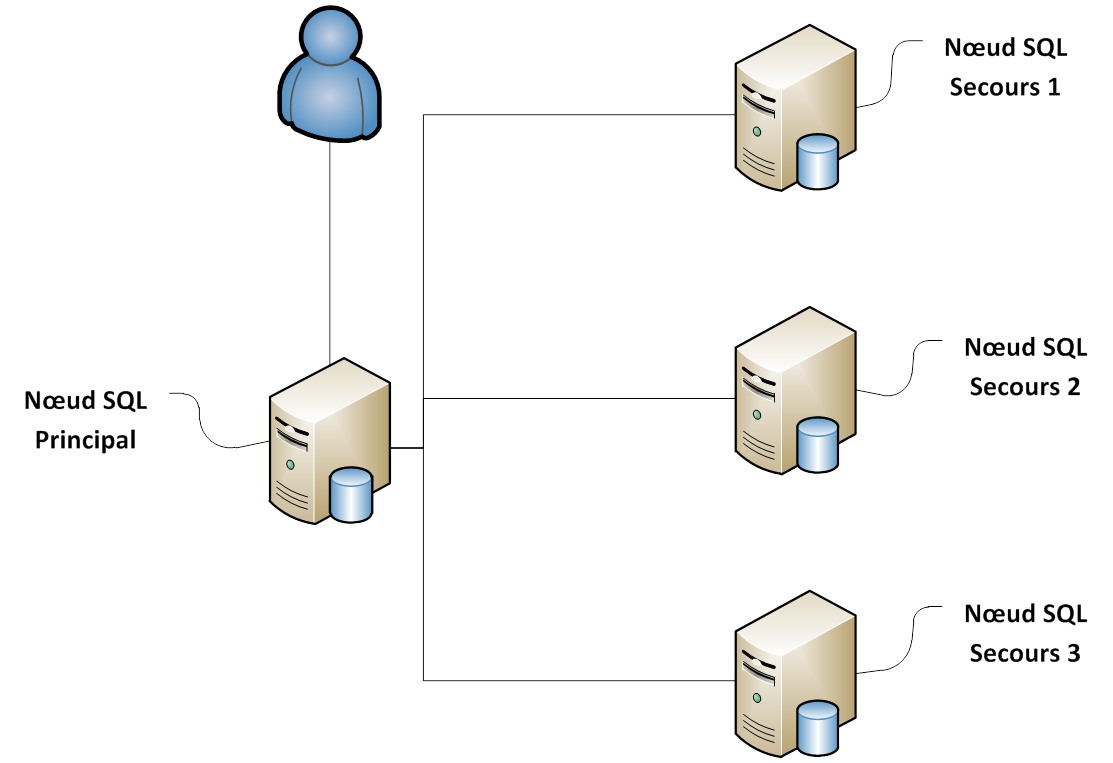
Dans ce système, les clients vont accéder à la base de donnée sur un serveur SQL appelé "Serveur Principal". Cette base de données va ensuite être répliquée sur un ou plusieurs serveurs appelés "Serveur de secours".
En cas d'indisponibilité du serveur principal, il suffira d'activer un des serveurs de secours et de rediriger les demandes sur ce serveur afin que la base puisse être de nouveau accessible. Cette manipulation est
à la charge de l'administrateur du système et prend en général quelques minutes.
Il existe deux système de réplication pour les bases de données :
- La réplication synchrone qui assure une réplication sans perte de données
- La réplication asynchrone qui permet de meilleurs performances mais avec un risque de perte de données
La réplication synchrone
Dans le cas d'une réplication synchrone, les commit sur la base de données doivent être effectués sur tous les serveurs de secours avant d'être fait sur le serveur de secours. Ce procédé induit un plus grand trafic réseau dû à la communication permanente entre le serveur principal et les serveurs de secours ainsi qu'un risque que le serveur principal se coupe si il n'y plus de serveur de secours disponible. Cependant ce système offre la garantie qu'aucune donnée ne sera perdu en cas de bascule entre le serveur principal et un serveur de secours.
La réplication asynchrone
Dans le cas d'une réplication asynchrone, les commit sur la base de données sont effectués immédiatement sur le serveur principal sans se préoccuper de savoir si ils ont été effectués sur les serveurs de secours. Ce procédé permet d'éliminer le risque de blocage de la base sur le serveur principal si il n'y a plus de serveur de secours disponible, le trafic réseau est aussi diminué entre le serveur principal et les serveurs de secours par l'absence des acquittements des commit. L'inconvénient posé par ce type de réplication est qu'il y a un risque de perte de donnée lors de la bascule entre le serveur principal et un des serveurs de secours.