Les clusters de calculs
Les réseaux hautes performances pour clusters
Pourquoi des réseaux hautes performances ?
Les clusters de calculs fournissent une énorme puissance pour traiter les données et par conséquent, l'échange de données doit se faire très rapidement entre les machines afin que du temps CPU ne soit pas gâché.Nous verrons donc dans cette section pourquoi les technologies réseaux tels que Ethernet / TCP IP ne sont pas adaptés, puis quelles technologies sont réellement utilisées dans ces réseaux.
Les faiblesses des technologies classiques
La pile de protocole TCP / IP est aujourd'hui celle qui fait foie dans le domaine des réseaux de communications informatiques. Les réseaux locaux, d'entreprises et même internet sont basées dessus. Cependant il s'avère que cette technologie n'est pas adaptée aux énormes besoins des clusters de calculs.TCP / IP est née dans les années 70 et a connu que très peu d'évolutions depuis. L'IP V4 est instauré depuis bien des années et la version 6 tarde à se généraliser. Les technologies de commutation (couches 2), Ethernet principalement, ont quant à elles été améliorées, principalement au niveau de la vitesse en passant de quelques Mégabits à aujourd'hui 10 Gigabit mais cela ne suffit pas. Il s'avère en effet que ces technologies on été conçus à la base pour les réseaux peu fiables tels qu'Internet qui utilise des lignes souvent hasardeuses. L'accent à donc été mis lors de leurs créations sur le contrôle de flux, la reprise sur erreurs, si bien que ces protocoles ne se sont pas imposés pour le calcul de masse car ils sont trop sophistiqués et du coup pas assez rentable au niveau du débit réellement exploitable.
De plus cette complexité vient engendrer des consommations excessives de temps CPU en raison du traitement protocolaire. Il faut en effet décapsuler toutes les couches une par une pour en extraire l'information, vérifier et calculer des codes de vérifications (checksums) ce qui prend du temps.
L'efficacité au niveau du transfert n'est pas le seul problème de ce type de technologie. La programmation système et l'utilisation du socket est également remise en cause par les expert en réseaux Hautes performances.
Les techniques traditionnels de socket induisent des consommations CPU lourdes et des pertes de temps en raison des copies systématiques dans une mémoire tampon: le socket buffer.
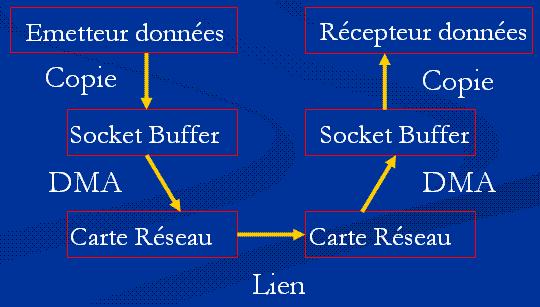
Comme on peut le voir sur le schéma ci-dessus, chaque fois que la machine doit envoyer une information sur le réseau, elle doit tout d'abord la copier dans le socket buffer, ce qui fait perdre du temps CPU. Une fois les données copiées, un appel DMA (Direct Memory Access) est lancé vers la carte réseaux pour qu'elle les transfert réellement sur le média, ceci consomme a nouveau du temps CPU.
A la réception de l'information, le problème reste le même, dans l'autre sens: la carte réseau copie les informations par DMA dans le socket buffer et il y a ensuite lecture de ce dernier par le système central.
Une autre faiblesse de la programmation réseau "standard" réside dans le manque d'efficacité des traitements lors de nombreuses connexion simultanées. L'utilisation de poll pour scruter si il y du trafic en provenance des connexions n'est vraiment pas optimale car cela induit le parcours de tous les descripteurs régulièrement. Des travaux on été mené dans ce domaine notamment avec les threads ou avec Epoll mais ils restent très peu convaincant.
Enfin il existe également un réel problème de latence en raison des accès à la carte réseau par le système central.
Tout ceci mis bout à bout, il s'avère donc que les technologies classiques issues d'internet et des réseaux locaux ne sont pas adaptées aux réseaux hautes performances, pour lesquels le temps CPU est très précieux.
Message Passing Interface (MPI)
Afin d'optimiser les transferts de données pour les clusters, une interface a été développée afin qu'il y ai une implantation commune pour les différents constructeurs. Il s'agit de l'interface MPI, dédiée au calcul parallèle et qui permet d'optimiser au maximum le temps processeur utilisé lors des transferts de données sur le réseau.
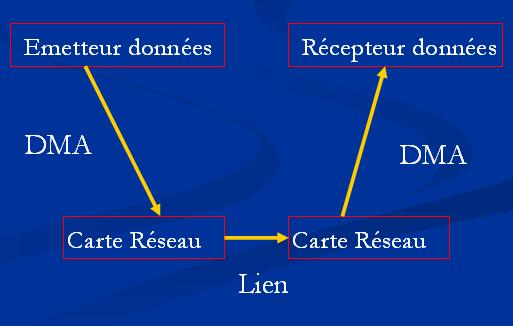
La philosophie communes à toutes les interfaces haute performance et que reprend bien entendu MPI est de déléguer au maximum les traitements réseaux à l'interface réseau afin que le processeur central en soit dispensé. MPI est basé sur le principe du "rendez-vous". Des messages asynchrones sont envoyés entre le processeur et l'interface réseaux. Le processeur demande l'expédition de données à l'interface et n'est pas bloqué durant le transfert, il poste ensuite régulièrement des messages pour savoir si le transfert est terminé ou non.
![]()
Les copies couteuses dans un socket buffer sont ici bannies. On appel cela le "zero-copy". Les données sont copiées de la mémoire centrale directement vers l'interface réseaux sans surcharger le processeur.
L' "OS bypass" est également utilisé. Cette technique permet de faire intervenir au minimum le système d'exploitation de la machine lors de la communication réseau des logiciels de calculs. Ces derniers accèdent directement à la carte réseau sans passer par le système d'exploitation. Ceci évite les interruptions processeur et économise donc ce dernier.
Enfin ce qui concerne le transfert des informations sur le média, des optimisations sont réalisées au niveau de la communication et du routage en privilégiant les comportements et donc les chemins déterministes. Ceci évite les phénomènes de congestion et donc évite que les machines attendent l'information à traiter.
Remote Direct Memory Access (RDMA)
RDMA est une technique qui nest pas implanté dans MPI et qui pose donc parfois de problèmes de compatibilité. Cependant si elle est utilisée proprement, elle peut savérer très performante.
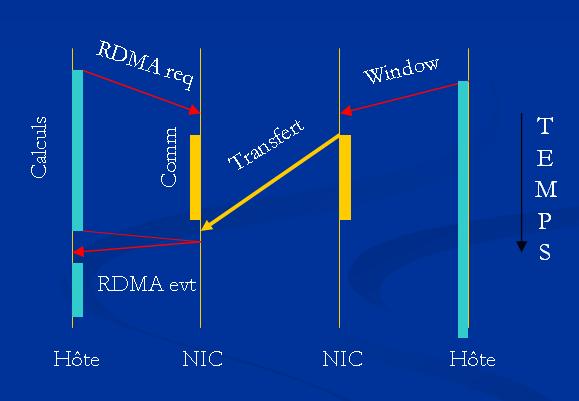
Il sagit en fait du concurrent du paradigme du « rendez-vous ». Ici, une machine peut accéder directement à la mémoire centrale dune autre machine. Lattente est active, il ny a pas de notification, chaque nud doit interroger régulièrement sont interface pour savoir si des évènements sont en attente. Cette technique est utilisée dans InfinyBand, QsNet et Sci.
Les différentes technologies hautes performances
Depuis le milieu des années 90, plusieurs constructeurs se sont lancés dans le développement de technologies réseaux visant à mieux supporter les quantités d'informations échangées au sein des clusters de calculs. Nous allons ici présenter les plus intéressantes (en rouge):

SCI

SCI est une technologie de la société Dolphin, crée au début des années 90. SCI est l'une des premières vrai technologies orientées hautes performances. Elle utilise une topologie en anneau et des connectiques propriétaires. C'est la technique RDMA qui est utilisée ici. Malgré une augmentation de la bande passante depuis peu, celle-ci reste inférieur à celle des technologies plus ressente (700 Mo/s). La latence plafonne à 1.4 µs ce qui est très bon. Son principal défaut est sa mauvaise compatibilité avec MPI.
Myrinet

Myrinet est une technologie de la société Myricom, qui date de 1995 et est la technologie leader du marché actuellement. Elle utilise une topologie en clos, permet datteindre 1,2 Go/s unidirectionnel et saccommode très bien des clusters comportant un très grand nombre de nuds (le MareNostrum au Barcelone Supercomputing Center est composé de 2282 nuds). La latence est elle denviron 2 micros secondes. Son avantage réside dans le fait que lémulation Ethernet TCP /IP est parfaitement supporté, ce qui permet davoir un réseau multifonctions (la connectique est en RJ45) de plus, MPI est très bien supporté sur la version MX.
QsNet
QsNet est une marque de la société Quadrics. Cette technologie permet datteindre un débit théorique de 900 Mo/s en full duplex grâce au bus PCI-express. La latence est de 2 micros-secondes. Il y a peu de recherche sur cette technologie car les spécificités ne sont pas ouvertes. En revanche elle est assez performante dans sa conception. En effet la traduction des adresse virtuelles / physiques pour les zones de mémoire est réalisée directement par la carte réseaux grâce à une MMU, qui est généralement réservée aux processeurs centraux, elle est de plus bien compatible avec MPI malgré lutilisation de RDMA. Un super calculateur reposant dessus est présent à Bruyère le château (60 teraflops).
Infiniband

Il sagit de la dernière technologie apparue. Elle est issue de deux projets : Futur I/O (Compaq, IBM et HP) et System I/O (Intel, Microsoft et Sun). Elle devait initialement reposer sur un tout nouveau bus mais Intel ayant décidé de se focaliser sur le PCI-Express, ce dernier a finalement été adopté. Cette technologie se caractérise par une très bonne efficacité au niveau de la bande passante, on estime 80 % les données utiles pour un transfert. Elle est plus proche dIP (adresses de niveau 2 et 3), la topologie nest pas fixée est le routage seffectue au niveau des commutateurs. Le débit peut atteindre 96 Gbit/s avec 4 liens.