Les clusters de calculs
Message Passing Interface (MPI)
Qu'est ce que MPI ?
MPI (actuellement en version 2) est un outil du domaine public.
Il permet à un ensemble de machines informatiques connectées sur un réseau local ou distant de se conduire comme une seule et même ressource permettant d'effectuer des opérations de calcul parallèle.
Une application MPI est un ensemble de processus autonomes exécutant chacun leur propre code et communiquant via des appels à des routines de la bibliothèque MPI.
MPI est une spécification du domaine public : il existe donc diverses implémentations pouvant être installées sur un grand nombre d'architectures.
Architecture
A la différence de PVM, MPI n'introduit que des fonctionnalité orienté communication, il n'y a donc pas de virtualisation des ressources.
MPI se base sur une définition de cluster sous forme de topologie et de communicateur:

Topologie MPI
MPI met en avant différentes fonctionnalités et propriétés visant à normaliser l'existant:
- mise en commun des avantages existant
- sémantique précise, sans choix d'implantation
- portabilité, puissance d'expression et bonnes performances
- description sophistiquée (types personnels, structure, réordonnancement à la volée)
- efficacité et lisibilité
- définition de topologie virtuelle
- topologie en grille ou graphe en vue d'une répartition efficace des processus
Spécifications principales
MPI possède sa propre bibliothèque de messagerie intégrant un grand nombre de routines de communications, mais aussi de gestion, d'I/O, etc...
Toutes les opérations effectuées par MPI portent sur des communicateurs. Le communicateur par défaut est "MPI_COMM_WORLD" qui comprend tous les processus actifs.
On peu distinguer 2 grandes classes de communication:
- les communication dite point à point ayant lieu entre deux processus.
- Les communications collectives permettant de faire en une seule opération une série de communications point-à-point. Elles concernent toujours tous les processus qu'un communicateur regroupe.

Communication point à point
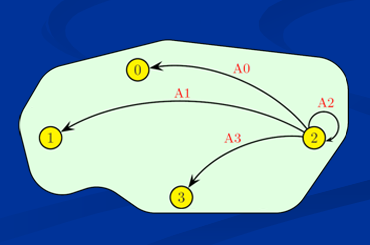
Communication multipoint
Exemple
Voici un exemple simple de programme démontrant la simplicité des communications via MPI.
Chaque processus peut communiquer en faisait référence à son numéro dans le communicateur (MPI_COMM_WORLD dans notre cas).
Ici, le noeud maître envoie un entier lu sur l'entrée standard à chaque esclave.
#include "mpi.h"
int main(int argc,char** argv)
{
int myrank, nprocs, n, islave, master;
MPI_Status status;
int ierr, resultlen;
char hostname[MPI_MAX_PROCESSOR_NAME];
MPI_Init(& argc, & argv);
MPI_Comm_rank(MPI_COMM_WORLD, & myrank);
MPI_Comm_size(MPI_COMM_WORLD, & nprocs);
MPI_Get_processor_name(hostname, & resultlen);
t0 = MPI_Wtime();
MPI_Barrier (MPI_COMM_WORLD);
t1 = MPI_Wtime();
// partie maitre: lit un entier sur l'entrée standard
if ( myrank == 0 )
{
printf("input n:");
scanf("%d",& n);
for(islave=1 ; islave < nprocs ; islave++)
{
ierr = MPI_Send(& n, 1, MPI_INT, islave, 10, MPI_COMM_WORLD);
if(ierr != 0)
{
printf("coin ! slave %d -> erreur %d\n", islave,ierr);
MPI_Abort ( MPI_COMM_WORLD, 99 );
}
}
}
// partie esclave: recoit le message avec l'entier
else
{
master = 0;
ierr = MPI_Recv (& n, 1, MPI_INT, master, 10, MPI_COMM_WORLD, MPI_STATUS_IGNORE );
if(ierr == 0)
{
printf("input from master: %d\n", n);
}
else
{
printf("coin ! slave %d -> erreur %d\n", islave,ierr);
MPI_Abort ( MPI_COMM_WORLD, 99 );
}
}
MPI_Finalize();
}