Calcul générique sur GPU
Progammation GPGPU
Modèle de programmation
La carte graphique (GPU) ou device est utilisée comme "co-processeur" de calcul pour le processeur de la machine hôte, le PC typiquement ou host (CPU).
La mémoire du CPU est distincte de celle du GPU mais on peut faire des recopies de l'un vers l'autre (couteux).
Une fonction calculée sur le device est appelée kernel (noyau)
Le kernel est dupliquée sur le GPU comme un ensemble de threads - cet ensemble de threads est organisé de façon logique en une grid.
Chaque clône du kernel connaît sa position dans la grid et peut calculer la fonction définie par le kernel sur différentes données.
Cette grid est mappée physiquement sur l'architecture de la carte au runtime.
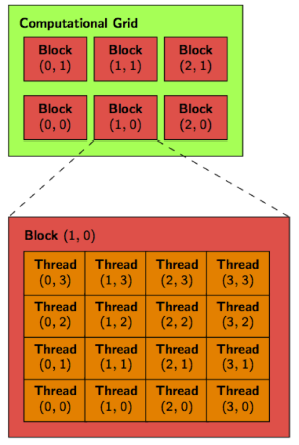
Une grid est un tableau 1D, 2D ou 3D de "thread blocks" - au maximum 65536 blocks par dimension (en pratique, 2D...) et chaque thread block est un tableau 1D, 2D ou 3D de
"threads", chacun exécutant un clône (instance) du kernel.
Chaque block a un unique blockId et chaque thread a un unique threadId (dans un block donnée).
CUDA
Taxonomie
Device : carte graphique (GPU) utilisée comme coprocesseur de calcul
Host : CPU de la machine hôte (mémoire CPU différent de mémoire GPU)
Kernel : fonction calculée sur le Device
Grille : mappage physique sur l’architecture du GPU
SM (Streaming Mutliprocessors) : ensemble de Streaming Processors, une instruction à la fois est appliquée aux SPs
SP (Streaming Processors) : composant effectuant une instruction par cycle
Créé en 2007 par NVIDIA, CUDA (Compute Unified Device Architecture) est composé d’un Framework, d’un ensemble d’outils et d’une extension du langage C. Il propose au développeur d'utiliser la puissance de calcul d’une carte graphique pour certaines opérations destinées à être traitées par le GPU au lieu du CPU. Ce dernier est d’ailleurs toujours nécessaire pour coordonner le travail CPU et GPU. Le GPU est ainsi vu comme un coprocesseur massivement parallèle très bien adapté au traitement d’algorithmes parallélisables, très mal aux autres.
L’exécution d’un programme CUDA s’effectue de la façon suivante :
1. Le programme est exécuté par le CPU
2. Un kernel est invoqué, son exécution se déplace sur le GPU
3. Un grand nombre de threads sont générés et exécutés en parallèle sur le GPU
| Avantages | Inconvénients |
|---|---|
| multiplateformes (Windows, MacOS, Linux) | propiétaire NVIDIA (GPU NVIDIA uniquement) |
| niveau de maturité avancé | |
| runtime api simple |
Architecture API
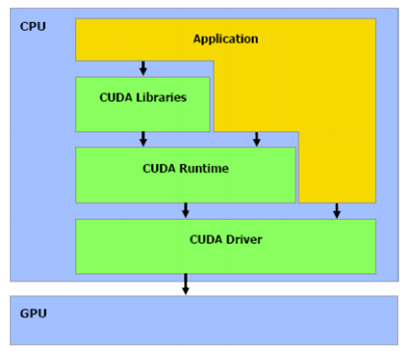
CUDA est composé d’un driver, d’un runtime et de librairie pour le langage C. Ainsi, on retrouve une API haut niveau avec le runtime et une API bas niveau avec le driver.
Architecture kepler
Derrière cette technologie, se cache une couche logicielle destinée au stream processing : paradigme de programmation lié au mode SIMD (Single Instruction Multiple Data) permettant à certaines applications d’exploiter la programmation parallèle.
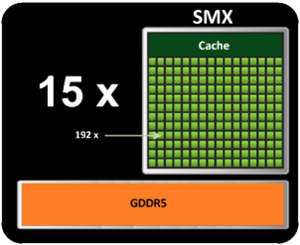
Ainsi, dans cette architecture, un GPU est composé de :
- 15 SM
- 1 SM est composé de 192 SP = coeur
- 1 SM possède une mémoire partagée entre tous les SPs
Execution d'un programme
L’API CUDA permet de répliquer au niveau logiciel les spécificités de l’architecture matérielle GPU et de gérer la communication entre CPU et GPU. Cela permet de voir logiciellement le GPU comme une grille de calcul à une ou deux dimensions, formée de blocs de calcul indépendants.
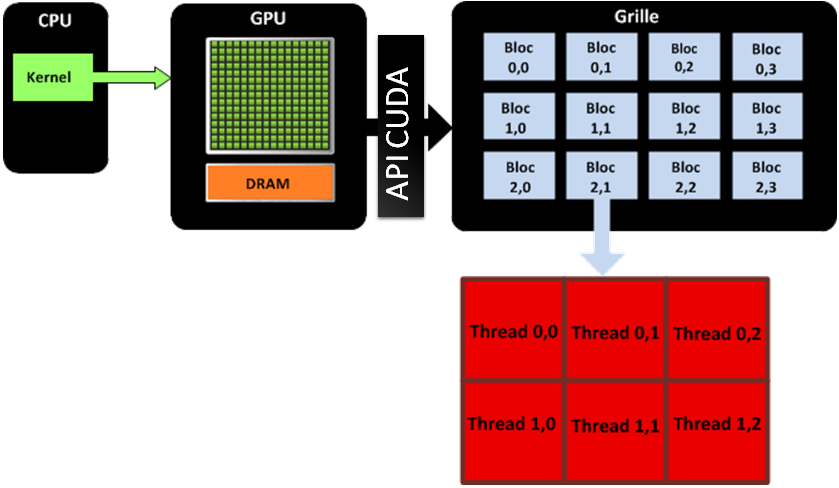
Un block représente une matrice de threads à 1, 2 ou 3 dimensions. Le développeur choisit les dimensions dont il a besoin.
Un block contient 128 threads et chaque thread exécute une instance dun kernel et a des coordonnées dans ce block pour identifier le thread.
OpenCL
Le consortium industriel Khronos group regroupe 90 entreprises en 2014 et sont à l'origine des standards OpenGL, WebGL, OpenCL et bien d'autres.
Créé en 2008 par Khronos group, ce framework a pour objectif d'exploiter les architectures parallèles (processeurs multi-coeurs + GPU).
Apple à été à l’origine de la proposition et est très actif (éditeur des spécifications).
| Avantages | Inconvénients |
|---|---|
| GPU supportés : NVIDA, ATI et ARM | API verbeuse |
| CPU supportés : Intel, PowerPC et Cell | framework jeune |
| multiplateformes (Window, MacOS, Linux, Android, IOS) | |
| standard ouvert |
Architecture
L'architecture d'OpenCL se compose de la manière suivante :
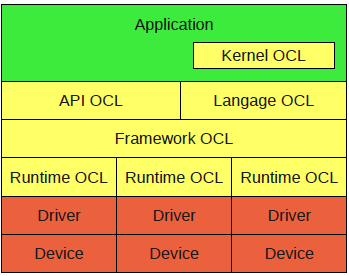
Elle reste analogue à celle de CUDA, on retrouve un driver et un runtime pour la partie bas niveau. Le framework OpenCL est contrôlé par le programme exécuté par le CPU via une API plus haut niveau.