jOpenDocument
Représentation d'un fichier en mémoire
Présentation
Passons maintenant aux choses sérieuses, on se doute bien après avoir vu la description du format OpenDocument que la librairie jOpenDocument doit mapper des fichiers XML.
Il existe deux méthodes bien connues pour manipuler du XML. SAX et DOM, voyons la différence entre ces deux méthodes et laquelle à été choisie dans jOpenDocument.
SAX
SAX est une API basée sur un modèle événementiel, cela signifie que SAX permet de déclencher des événements au cours de l'analyse du document XML. Une application utilisant SAX implémente généralement des gestionnaires d'événements, lui permettant d'effectuer des opérations selon le type d'élément rencontré.
Il existe plusieurs librairies permettant d'implémenter SAX facilement, mais il est implémenté nativement dans je JDK de JAVA.
DOM
Dom est une API Il utilisant une approche hiérarchique : il construit en effet une structure hiérarchique contenant des objets représentants les éléments du document, et dont les méthodes permettent d'accèder aux propriétés.
La librairie JAVA utilisant DOM est jDom, une librairie open source disponible ici.
jDom est la librairie utilisée dans jOpenDocument, les développeurs ont en effet choisis jDom car il permet de mapper tout le fichier en mémoire, l'accès aux données est du coup beaucoup plus simple qu'avec SAX.
Représentation en arbre avec jDom d'une feulle de calcul
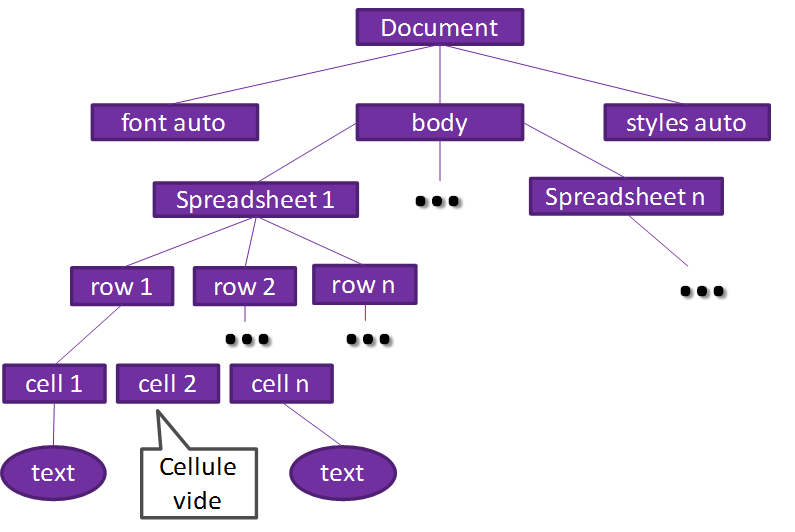
Dans cette représentation sous forme d'arbre, on voit la représentation des données XML. Voici la comparaison avec le code XML: Si on réduit les données du fichier XML, voici ce qu'on obtient :
<office:document-content> <office:font>...</office:font> <office:automatic-styles>...</office:automatic-styles> <office:body>...</office:body> </office:document-content>
Si on regarde le schéma, on voit bien la balise root <office:Document-content>.
On retrouve dans cette balise la font automatique, le style automatique et le body, intéressons nous au contenu de la balise body:
<office:body> <office:spreadsheet> <table:table table:name="Feuille1"> <table:table-row> <table:table-cell office:value-type="string"> <text:p>Titre :</text:p> </table:table-cell> <table:table-cell office:value-type="string"> <text:p>Calendrier vacances 2012</text:p> </table:table-cell> <table:table-cell/> <table:table-cell office:value-type="string"> <text:p>Version :</text:p> </table:table-cell> <table:table-cell office:value-type="string"> <text:p>0.4</text:p> </table:table-cell> </table:table-row> <table:table-row>...</table:table-row> </table:table> </office:spreadsheet> <office:body>


Comme sur le schéma, on voit l'architecture des données: Document, body, Spreadsheets(onglet excel), lignes puis cellules. On voit que la balise cell vide représente une cellule vide dans le fichier (voir la balise C1 en vert).