Les logiciels de gestion de version décentralisés
Les critiques du modèle centralisé
Dans cette partie, je vais illustrer certains propos avec le logiciel de gestion de version SVN. En effet, c'est le logiciel référent dans sa catégorie. Il est sans aucun doute le plus simple à prendre en main, le plus utilisé et le plus connu des logiciels libres. Il est souvent pris référence lorsque l'on aborde le sujet des DVCS.
L'accès au dépôt
Le mode centralisé fonctionne selon le mode Client-Serveur. Plus précisément, il fonctionne en mode connecté, les actions proposées par l'outil se font donc au travers du réseau. A première vue, rien d'anormal, il s'agit du fonctionnement classique d'une architecture Client-Serveur. Seulement tout l'historique du projet étant sur le dépôt, on ne travaille qu'avec une copie d'une version particulière du projet sur son espace de travail. Par conséquent, les actions les plus basiques comme effectuer un commit, poser un label sur une révision, effectuer des comparaisons entre deux fichiers pour voir ce qui a changé sont impossibles si le dépôt central est inaccessible.

Une panne de réseau dans l'entreprise ? Le site internet qui héberge votre dépôt fait une maintenance le jour où vous devez livrez ? Le serveur de l'université qui héberge votre projet à rendre dans 4h est down, sachant qu'aujourd'hui c'est dimanche et que le CRI ne travaille pas le weekend ☺... Autant d'exemples qui montrent que ce mode connecté dans certains cas peut s'avérer contraignant.
Le dilemme du développeur SVN
L'historique du projet étant linéaire, on ne peut ajouter une révision sur le dépôt que si ce sur quoi on travail est basé sur la dernière révision du dépôt. Voici alors ce qui arrive souvent dans les projets avec de nombreux committers :
... svn update # modification du code svn update # résolution des conflits pour se synchroniser avec la dernière version présente sur le dépôt svn commit # oops ! quelqu'un a commité pendant ma résolution de conflits svn update # résolution des mêmes conflits...encore svn commit # oops ! quelqu'un d'autre à commité :-@ ...
Ce cycle peut durer un temps certain et répété n fois dans la journée devenir irritant.
Plus encore, lorsque l'on travaille sur une correction de bogue ou une petite fonctionnalité, en quelques heures le travail peut être fini et on envoi alors ses changements dans le dépôt. Si l'on travaille sur une plus grosse tâche, plusieurs jours de travail voire plusieurs semaines sont nécessaires pour en arriver au bout. On se retrouve alors fréquemment face au dilemme suivant :
- Committer un état pas stable de son travail : ça ne compile peut être pas, tous les tests ne sont pas OK, il y a peut être un problème de dépendances dans les librairies du projet...
- Ne pas effectuer de commit avant d'avoir un état stable de son travail
Aucune des deux solutions ne semble être la bonne. Dans le premier cas, vous perturbez le travail des autres membres de l'équipe de développement et dans le deuxième vous prenez le risque de ne pas versionner votre travail pendant des jours voir des semaines. Ce dilemme intervient car versionner et partager sont traités comme étant la même opération par SVN, bien qu'étant deux concepts différents. Ce qui fait que l'on est constamment impacté par le travail des autres. Que ce soit positivement pour se synchroniser avec son équipe ou négativement quand on veut juste versionner un fichier.
La gestion des révisions et des merges
Pour SVN, elle est orientée fichier. Lorsque l'on crée une version d'un fichier, celui-ci sera identifié par son chemin d'accès ainsi que le numéro de version auquel il appartient. SVN associe à ce fichier un répertoire contenant des fichiers de propriétés, le répertoire caché .svn. Ce répertoire, qui lui aussi est versionné, se trouve dans tous les sous-répertoires du projet.
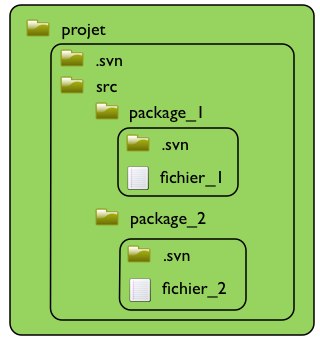
Ce mode de fonctionnement pose problème pour gérer efficacement l'historique d'un fichier ou d'un répertoire qui a été déplacé ou renommé lors d'opérations de refactoring important ou de fusion de branches. Pour comprendre ce qu'est une fusion de branche, il faut comprendre ce qu'est une branche.
Définition d'une branche
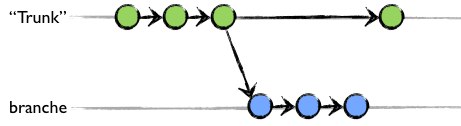
Une branche est un développement en parallèle du projet. Un exemple : imaginons un produit, deux clients. L'un des deux clients demande juste la fonctionnalité en plus par rapport à l'autre, il n'y a que cette fonctionnalité qui diffère par rapport à l'ensemble du projet. Intuitivement, ce que l'on est tenté de faire, c'est de prendre le projet, d'en faire copie dans un autre répertoire et de maintenir les deux projets en parallèle. C'est ce que fais SVN littéralement lorsque l'on fait une branche, il prend le répertoire principal et le copie dans un autre répertoire. Cette opération revient à modifier le chemin des fichiers qui sont versionnés.
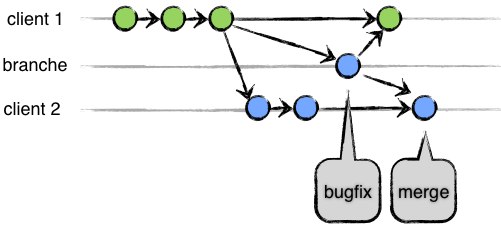
Or le problème intervient lorsque l'on souhaite fusionner ces branches (pour répercuter une correction de bogue par exemple) et que sur une branche il y a eu des changements dans l'arborescence du projet. C'est cette gestion parfois douloureuses des branches (et de leur fusion) qui fait principalement défaut à SVN. Voyons comment toutes ces critiques ont été gérées par les logiciels de gestion de version distribuées.
La réponse DVCS >>>