Git, gestionnaire de version dťcentralisťe
Fonctionnement de Git
Prťsentation de Git
Git est un gestionnaire de version dťcentralisťe. Il a ťtť crťť par Linus Torvarlds ťgalement crťateur
du noyau Linux. Ce projet est sous licence GPL et est principalement dťveloppť en C avec ťgalement un peu
de Shell et de Perl, notamment pour les "hook scripts".
Git est dŤs ŗ prťsent utilisť par de nombreux projets. Certains d'entre eux ont migrť vers Git rťcemment.
Nous pouvoir par exemple citer :
- Kernel.org : Le kernel Linux
- VLC : Le lecteur multimťdia
- Samba : Pour le partage de fichiers Windows/Linux
- X.org : Le serveur graphique
Pourquoi Git ?
A l'origine, Linus Torvarlds ŗ dťveloppť Git pour proposer une alternative libre a un gestionnaire de version dťcentralisťe baptisť BitKeeper. Git s'est dťsormais imposť dans ce domaine pour plusieurs raisons :
- Sa rapiditť
- Sa robustesse
Gr‚ce a git, n'importe qui est en mesure de :
- Cloner un repository
- Effectuer/Commiter des changements en local
- Gťnťrer des patchs
- Envoyer ses changements "upstream" si il en a les droits
- Suivre le dťveloppement "upstream"
Parmi ses autres avantages, nous pouvons ťgalement citer :
- Les identifiants universels de commits (SHA1), permettant ainsi d'identifier un objet git de faÁon unique. Que ce soit un fichier, un rťpertoire, un commit etc.
- Il est multi-protocole, les ťchanges entre repository peuvent se faire via http(s), ssh, rsync, ou encore en utilisant le protocole Git lui mÍme.
- Un stockage des objets efficace gr‚ce a la compression. Permettant ainsi de sauver beaucoup d'espace disque
- Tout le monde dispose du repository entier, et peut ainsi consulter les logs et/ou changements entre les rťvisions sans qu'il soit nťcessaire de se connecter a un serveur maÓtre.
- Et enfin, git est trŤs efficace pour la gestion de branches de dťveloppement.
Structure d'un repository git
Voici les diffťrents objets stockťs dans un repository git.
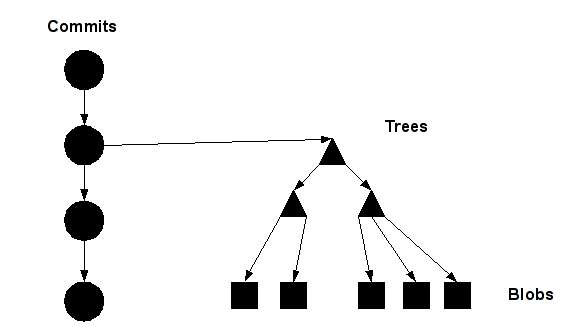
Nous avons donc :
- Les blobs, qui reprťsente en rťalitť un fichier, ou plutŰt une version bien prťcise d'un fichier
- Les trees, qui sont en fait des rťpertoires, contenant des objets blobs, comme dans tout systŤme de fichiers
- Les commits, le nom parle de lui mÍme
- Les tags, un tag peut Ítre associť ŗ un commit, afin de l'identifier plus simplement
Recherchons dans un premier temps un commit sur lequel fonder notre exemple. Pour cela lanÁons la commande git-log qui nous affiche les commits du projet, choisissons en un par son identifiant SHA1.

Une fois notre commit exemple choisit, analysons sont contenu par le biais de la commande git-cat-file avec l'option "-p". Cette commande de git est en quelque sorte une commande de bas niveau, nous permettant d'analyser le contenu brut d'un objet git.

Dans le contenu de ce commit, nous pouvons dans un premier temps remarquer une rťfťrence ŗ un commit parent, ce qui parait plutŰt logique pour un gestionnaire de version. Et enfin ce qui nous intťresse le plus, la rťfťrence tree, qui est en fait une rťfťrence sur un rťpertoire contenant les objets de notre commit.
Affichons maintenant les informations sur le contenu de ce tree :
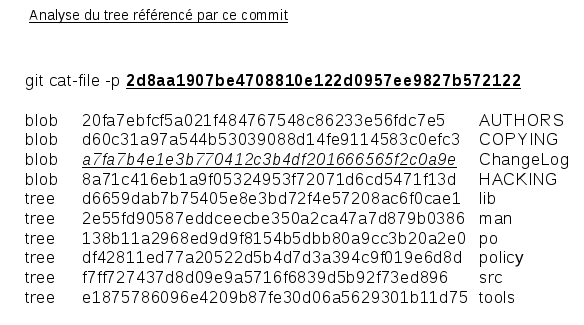
Ce tree contient bien entendu des blobs (fichiers), et ťgalement d'autre trees (rťpertoires), comme tout bon systŤme de fichiers. Sťlectionnons l'identifiant d'un blob, et affichons son contenu, toujours par le biais de la commande git-cat-file.

Nous avons maintenant le contenu du fichier. Il s'agit en fait du contenu du fichier "ChangeLog" dans son ťtat au moment du commit que nous avons sťlectionnť. Affichons maintenant le contenu actuel du fichier, pour voir si des changements ont ťtť effectuťs entre temps.

Le contenu actuel du fichier est similaire au contenu lors du commit sťlectionnť. Comme prťcisť prťcťdemment, git utilise avec une grande efficacitť la compression afin de limiter au maximum la taille de ses objets, et par consťquent la taille du repository. Lors de sa crťation, un fichier n'est pas compressť. Cependant, git se chargera de la compression lors de transferts. L'utilisateur peut aussi choisir d'effectuer une passe de compression de son repository via la commande git-repack. Cela ne prťsente pas d'avantage autre que celui de rťduire la consommation d'espace disque, puisque pour les transferts entre repository, la compression est utilisťe par dťfaut, comme prťcisť prťcťdemment.
Le rťpertoire .git
Dans le rťpertoire .git nous trouvons les fichiers/rťpertoires suivants :
- config/ : contient des fichiers relatifs ŗ la configuration de l'environnement git, comme par exemple des informations sur le dťveloppeur (son nom, son email ...)
- objetcs/* : c'est dans ce rťpertoire que sont stockťs tous les objets git (commits, tags, trees, blobs)
- ref/heads/* : contient les informations sur les branches locales du repository
- logs/* : contient les messages de logs
- refs/remotes/* : contient les informations relatives aux branches distantes, c'est ŗ dire les branches du repository depuis lequel nous avons clonť le projet. Si c'est un projet nouveau, alors il n'y a pas de branches distantes
- index : fichier contenant des informations sur l'ťtat du prochain commit (voir plus bas)
- HEAD : fichier contenant des informations sur la branche actuelle de l'utilisateur
Le fichier index
Le fichier index reprťsente le prochain commit de l'utilisateur. Lorsqu'un utilisateur
modifie, ou ajoute un nouveau fichier, il faut qu'il l'ajoute ŗ l'index pour qu'il soit
commitť.
Pour une meilleure comprťhension, voici un exemple d'utilisation du fichier d'index. Nous
avons donc notre repository, sur lequel nous n'avons pas encore fait de modifications non
commitťes. Nous pouvons le vťrifier par le biais de la commande "git-status" :
alk@macbook PackageKit % git status
# On branch master
nothing to commit (working directory clean)
Effectuons maintenant des modifications sur les fichiers ChangeLog et AUTHORS, et consultons le retour de la commande git-status aprŤs ces modifications.
alk@macbook PackageKit % vim ChangeLog alk@macbook PackageKit % vim AUTHORS alk@macbook PackageKit % git status # On branch master # Changed but not updated: # (use "git add..." to update what will be committed) # # modified: AUTHORS # modified: ChangeLog # no changes added to commit (use "git add" and/or "git commit -a")
Nous pouvons constater que git s'est bien rendu compte que les fichiers avaient ťtť modifiťs. Cependant, il prťvient l'utilisateur que ces changements ne seront pas commitť lors du prochain git-commit tant qu'ils n'auront pas ťtť ajoutťs ŗ l'index.
Pour tester, ajoutons un des deux fichiers ŗ l'index.
alk@macbook PackageKit % git add ChangeLog alk@macbook PackageKit % git status # On branch master # Changes to be committed: # (use "git reset HEAD..." to unstage) # # modified: ChangeLog # # Changed but not updated: # (use "git add ..." to update what will be committed) # # modified: AUTHORS #
Nous avons ajoutť le fichier ChangeLog ŗ l'index. Cela signifie que tous les changements apportťs ŗ ce fichier seront commitťs lors du prochain git-commit, alors que ceux apportťs au fichier AUTHORS (non ajoutť ŗ l'index) ne seront pas pris en compte.