Benchmarking et optimisations en Java
Prérequis théoriques
Mesure du temps d'exécution
En principe, la mesure du temps d'exécution suit un principe trivial :- Enregistrement de la date de départ
- Exécution du code
- Enregistrement de la date de fin
- Calcul de la différence
Typiquement, en Java, cela donnerait :

Cette méthodologie reste très valable pour des tâches longues, malheureusement un peu moins pour les tâches courtes, en raison de la résolution de l'appel currentTimeMillis().
En effet, la méthode currentTimeMillis() a une résolution avec un facteur variant de 10 à 100.
D'après la Javadoc, je cite :
"Note that while the unit of time of the return value is a millisecond, the granularity of the value depends on the underlying operating system and may be larger. For example, many operating systems measure time in units of tens of milliseconds."
Donc, comme nous pouvons le voir, cela dépend fortement du système d'exploitation sous-jacent.
Voici un tableau récapitulatif selon le type d'OS :
| Resolution | Platform | Source |
| 55 ms | Windows 95/98 | Java Glossary |
| 10 ms | Windows NT, 2000, XP single processor | Java Glossary |
| 15,625 ms | Windows XP multi processor | Java Glossary |
| ~15 ms | Windows (presumably XP) | Simon Brown |
| 10 ms | Linux 2.4 kernel | Marcus Kobler |
| 1 ms | Linux 2.6 kernel | Marcus Kobler |
Si l'on veut être raisonnable et rigoureux dans la mesure du temps d'exécution, il convient de fixer un pourcentage d'erreur lié à la résolution de l'appel qui ne doit pas dépasser 1%.
Ce qui nous amène à dire, logiquement, que la tâche étudiée doit au moins prendre 100 ms à s'exécuter sur un OS récent (Windows XP, Linux 2.4) pour respecter le quota précédemment cité.
Heureusement pour nous, une solution à ce problème existe, elle se nomme System.nanoTime(), et est une API introduite par le JDK 1.5.
Cette API de meilleure résolution est très utile pour les calculs différentiels, même si son référentiel est aléatoire (un appel peut renvoyer une valeur négative). La Javadoc assure à ce sujet-là des performances au moins égales à celles apportées par currentTimeMillis(), et la capacité d'avoir une précision en microsecondes sur un OS récent.
Conclusion
Il est très fortement conseillé d'utiliser systématiquement System.nanoTime() ( et de ne pas effectuer de benchmark sous Windows 95/98 ;) ).
Code Warmup ou "échauffement de code" pour les réfractaires à la langue de Shakespeare
Afin de mesurer les performances pures d'un code, il faut amener la JVM à un état d'équilibre, dont les facteurs sont les suivants :- Class Loading
- Mixed mode
Class loading
Le chargement des classes par la JVM se fait typiquement lors de leur première utilisation, impliquant :
- Des accès disques
- Du parsing
- De la vérification
*
Cette caractéristique impose d'être certain que toutes les classes soient chargées avant de mesurer le temps d'exécution.
Pour cela, il existe deux méthodes de la classe ClassLoadingMXBean, getTotalLoadedClassCount() et getUnloadedClassCount() dont les valeurs de retour doivent être comparées avant et après le benchmark.
A la moindre variation, il est nécessaire réexécuter la tâche jusqu'à obtenir une stabilisation des valeurs.
Mixed mode
Le terme mixed mode fait référence à la capacité de la JVM d'interpréter ou de compiler le byte-code directement en langage natif.
Lors de l'exécution d'un programme, la JVM effectue une phase de profilage pendant laquelle le code est purement interprété.
Puis, si un bloc de code est appelé plusieurs fois, elle décide de le compiler directement en code natif, on parle de compilation Just-In-Time. Typiquement, par défaut, cela intervient :
- En mode -server, après 10 000 appels au même bloc de dode
- En mode -client, après 1500 appels au même bloc de code
Il est important de savoir que la compilation est gourmande en termes de temps et de ressources, mais apporte un gain de performances non-négligeable, illustré par le graphique suivant :
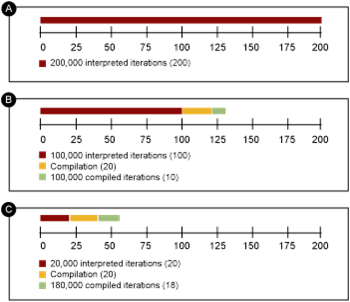
Conclusion
Pour conclure sur le Code Warmup, et la manière de dissocier le temps de traitement associé du temps réel d'exécution de la tâche, voici un listing des 6 étapes nécessaires pour arriver à ses fins.
- Lancer une exécution pour le chargement des classes
- Lancer plusieurs exécutions pour laisser le temps à la JVM de profiler la tâche
- Lancer plusieurs exécutions pour estimer la véritable durée de la tâche
- Calculer n, le nombre de fois où il faut lancer la tâche pour atteindre un temps raisonnable (résolutions d'appel, etc...)
- Mesurer le temps t qu'il faut pour exécuter la tâche n fois supplémentaires
- Estimer le temps de la tâche en divisant t par n
Remarque : Il n'existe pas de méthode parfaite pour le point 2, il est conseillé d'utiliser CompilationMXBean.getTotalCompilationTime() ou l'option -XX:+PrintCompilation, mais le choix d'un temps suffisamment grand peut convenir.