Apache Solr
Principe de fonctionnement
XML/HTTP
Le principe de Solr est de fonctionner grâce aux API XML/HTTP. En fait le dialogue avec le serveur se fait via le protocole HTTP. Ainsi pour ajouter un document à l'index, on utilise la méthode POST. Pour effectuer des recherches de documents, on utilise par contre la méthode GET.
Il y a alors deux points d'entrée principaux sur le serveur, correspondant à deux URL, puisqu'on utilise HTTP :
- URL update : http://localhost:8983/solr/update (maintien des index)
- URL select : http://localhost:8983/solr/update (requête de recherches de documents)
Nota : ici, le serveur est supposé tourner en local et le port 8983 est le port par défaut de Jetty.
Processus
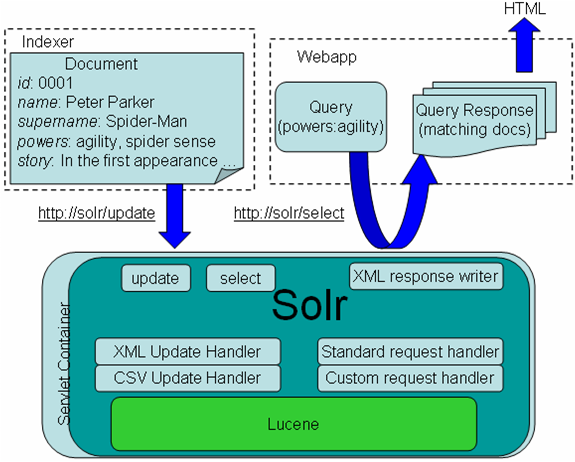
Dans le schéma ci-dessus, dans la partie gauche, on souhaite indexer un document concernant le super
héros Spiderman, identifié par un ID, un nom, un super nom, des pouvoirs et une histoire.
En dessous, est représenté Solr, dans son conteneur de servlets, avec Lucene comme socle.
On passe donc par l'URL update, puisque c'est un ajout d'un nouveau document. Ensuite, en fonction
de si le document est au format XML ou CSV, un handler effectue le traitement d'analyse de la requête.
Le plus souvent, c'est XML qui est utilisé.
La partie de droite concerne la demande de recherche de document. On passe donc par l'URL Select, en demandant
tous les superhéros qui détiennent le pouvoir d'agilité.
Un handler de requête permet de traiter la recherche, et la réponse est écrite en XML, via le
XML response writer.
Les documents qui matchent la requête sont ainsi renvoyés à l'application cliente, qui peut par exemple
retranscrire le tout au format HTML pour présenter les données.