ApEx : Application Express d'Oracle
Son fonctionnement
Après avoir présenté ce qu'était ApEx, nous allons désormais aborder son fonctionnement.
Le nécessaire
Pour fonctionner, ApEx a besoin d'une base Oracle dans laquelle tous ses composants vont être stockés.
Comment procède-t-il ?
Tout d'abord, il crée deux schémas dans la base qui va l'héberger:
- Un schéma nommé FLOWS_XXXXXX où XXXXXX est le numéro de version d'ApEx (ex: FLOWS_030000). Dans celui-ci sont stockés tous les objets relatifs à cette version d'ApEx.
- Un schéma FLOWS_FILES qui permet de gérer les objets commun aux différentes version d'ApEx tels que les styles CSS, les thèmes des applications, les images, les animations flash, etc.
A noter que si une nouvelle version d'ApEx venait à être installée, seul un nouveau schéma FLOWS_YYYYYY serait créé. Le schéma FLOWS_FILES contiendra les mêmes données.
Que contiennent réellement ces schémas?
Ces deux schémas stockeront les metadata composées de 215 tables, 200 objets PL/SQL et environ 300 000 lignes de code qui correspondent à ce que l'on appelle le "moteur" d'ApEx.
Les architectures
Désormais, nous allons voir comment fonctionne l'architecture d'ApEx, ou plutôt ses architectures car ApEx en propose deux différentes.
- Soit une architecture 3-tiers qui est présente depuis le lancement d'ApEx.
- Soit une architecture 2-tiers qui a été disponible avec la version 10.2.0.3.0 de la Release 2 des bases Oracle 10g mais qui a été intégrée officiellement avec les bases 11g pour ApEx.
L'architecture 3-tiers
Elle est composée de trois éléments:
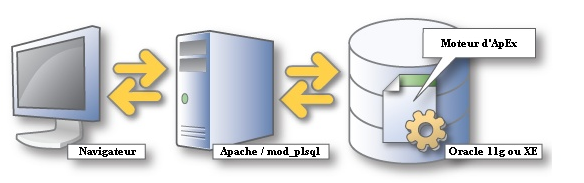
Figure 2 – L'architecture 3-tiers d'ApEx
- Le navigateur Web,
- Un serveur HTTP Apache muni d'un plug-in nommé "mod_plsql",
- Une base de données Oracle avec ApEx intégré à celle-ci.
Plus précisément, comment fonctionne ApEx avec cette architecture:
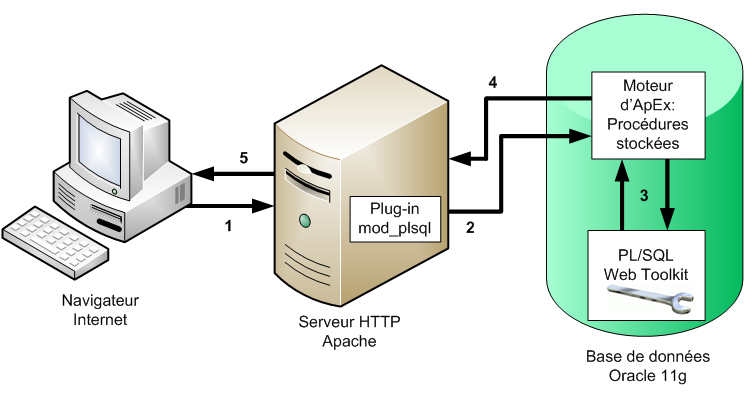
Figure 3 – L'architecture 3-tiers d'ApEx détaillée
Tout d'abord le client, avec son navigateur, va effectuer une action, par exemple presser un bouton ou déclencher une recherche dans une table.
- (1) Cela déclenche une requête HTTP qui est envoyée au serveur Apache.
- (2) Celui-ci va relayer cette requête, via une connexion SQL*Net, vers les procédures stockées du moteur ApEx grâce au plug-in mod_plsql.
- (3) Ces procédures stockées vont alors appeler des fonctions du PL/SQL Web Toolkit pour traiter la requête du navigateur. Le PL/SQL Web Toolkit est en fait une API réalisée en PL/SQL qui permet d'analyser la requête HTTP et de dialoguer avec la base de données pour récupérer, ajouter, supprimer, ou mettre à jour les données. Il va ensuite générer une page composée de code HTML qui correspondra au résultat de la demande de l'utilisateur. Cette page sera alors renvoyée aux procédures stockées d'ApEx.
- (4) Ensuite, le trajet en sens inverse s'effectue où ApEx va envoyer la page HTML générée au serveur Apache via la connexion SQL*Net du plug-in mod_plsql. Ce dernier va ensuite relayer l'information (5) au navigateur Internet afin que celui-ci affiche la page générée.
L'architecture 2-tiers
Elle est composée de deux éléments:
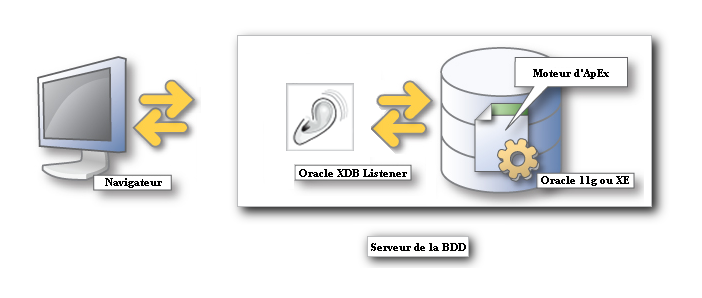
Figure 4 – L'architecture 2-tiers d'ApEx
- Le navigateur Internet,
- Un serveur sur lequel se trouve:
- La base de données contenant ApEx,
- Un listener HTTP se nommant Oracle XDB.
Plus précisément, comment fonctionne ApEx avec cette architecture:
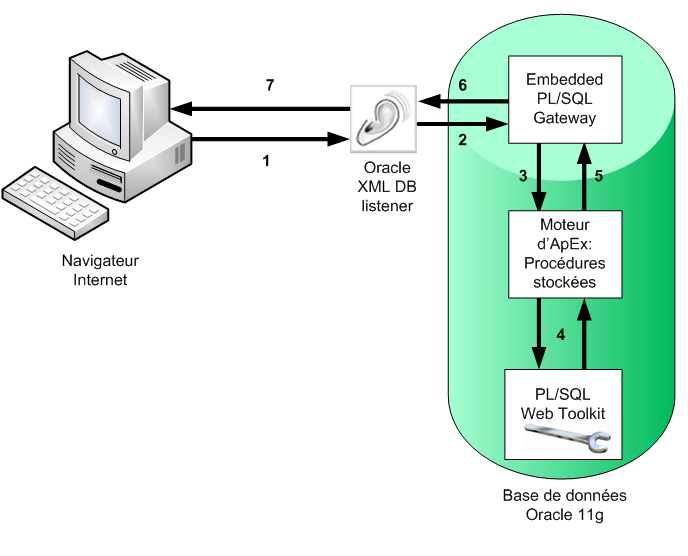
Figure 5 – L'architecture 2-tiers d'ApEx détaillée
- (1): Le XDB Listener reçoit une requête du navigateur du client.
- (2): Il route cette requête vers la passerelle PL/SQL intégrée (PL/SQL Gateway).
- (3): Cette passerelle va analyser les informations contenues dans la requête HTTP et appeler les procédures stockées correspondantes du moteur ApEx.
- (4): Puis, comme précédemment, le moteur ApEx va utiliser l'API PL/SQL Web Toolkit pour accéder aux informations de la base de données (et faire de la consultation, de l'ajout, de la mise à jour ou de la suppression de données) et générer la page HTML pour le client.
- (5): Cette page est récupérée par le moteur ApEx et envoyée à la passerelle intégrée.
- (6): Ensuite la passerelle envoie la page au XML DB Listener qui lui même fournit la page au navigateur du client (7).
Comparaison de ces deux architectures
Pourquoi choisir une architecture 3-Tiers ?
- Pour des questions de sécurité car l'architecture 3-Tiers peut être couplée à un Firewall. Dans ce cas, le serveur HTTP sera placé dans la DMZ et de serveur de Base de Données dans la partie réseau interne (LAN).
- Le plug-in mod_plsql qui est couplé au serveur Apache possède plus de fonctionnalités que le XDB Listener et permet notamment de faire du System Monitoring ou d'avoir un cache HTML dynamique.
Pourquoi choisir une architecture 2-Tiers ?
- Comme on a plus à s'occuper d'un serveur HTTP, cela simplifie énormément l'installation, la configuration, l'administration et la maintenabilité d'ApEx.
- Le XML DB Listener peut être utilisé pour d'autres applications de type "PL/SQL Web applications". Ce qui signifie que si l'on souhaite recoder notre propre moteur ApEx on pourra s'appuyer sur le listener XDB.
Par conséquent, le choix de l'architecture dépend vraiment de ce que l'on souhaite faire et de ce que l'on souhaite mettre en place.
Lorsque l'on a choisi son architecture et installé ApEx, nous allons pouvoir développer des applications.