La haute disponibilité logicielle via Heartbeat
 |
Exemples d'applications |
| "En théorie, il n'y a pas de différences entre la théorie et la pratique. En pratique, il y en a". (Chuck Reid) |
Les mécanismes expliqués précédemment sont génériques, et peuvent s'appliquer normalement à toutes les
architectures imaginables, comme des serveurs web,
serveurs de tamagotchis, ou tout ce que vous pouvez imaginer
d'autre. Attention toutefois, de petites subtilités pourront apparaître selon le type de service à faire
fonctionner sur les machines.
Les exemples qui suivent, de plus en plus complexes, vont vous faire entrevoir ces subtilités.
Relais de messagerie
Voici un premier exemple simple. Vous souhaitez mettre en place un relais de messagerie dans votre entreprise : un
petit serveur Linux sécurisé par vos soins, placé en frontal sur Internet, qui récupère tous les mails et les
envoie à votre serveur Exchange dernier cri.
Vous n'avez besoin que d'une seule machine pour faire tout le travail. C'est donc la solution la plus
simple, qui ressemblera à peu de choses près à ceci :
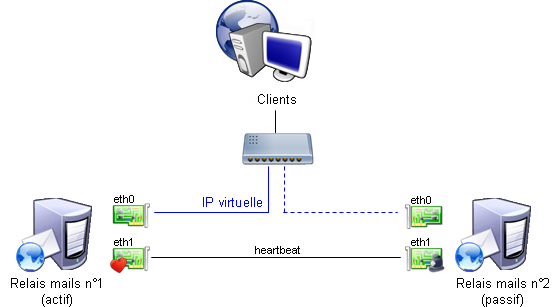
On notera l'utilisation de deux cartes réseaux sur les serveurs : une pour dialoguer avec les clients, et une pour envoyer les battements de coeurs et autres données liées à la haute disponibilité. Ceci n'est pas indispensable, mais offre quelques menus avantages :
- les données internes sont bien séparées des données des clients, et n'usent pas de bande passante inutile.
- les deux machines ne se mettront pas en mode "actif" en même temps en cas de défaillance du commutateur, routeur ou autre qui les relie entre elles.
Serveur Web
Votre employeur est ravi des performances du relais de messagerie, et aimerait faire de même avec son site web,
qui devient de plus en plus critique pour l'entreprise. Bien configuré, il suffit d'une seule machine pour
supporter la charge du serveur web. Vous vous dites-donc que deux machines suffiront. Mais ce n'est pas si simple !
En effet, survient le problème des sessions ! Une session,
comme vous le découvrez vite, est un mécanisme permettant d'identifier un utilisateur et de le suivre entre les
différentes pages pour lui proposer des services personnalisés, contrôler qu'il ne consulte pas de pages sensibles
ou autres. Et ces sessions sont dans la majorité des cas écrites sur la machine.
Si en lisant ces lignes vous venez de vous dire : "Ah, mais oui ! Ca ne va pas marcher du tout !", vous pouvez
sauter les paragraphes et vous rendre directement au schéma ci-après, vous venez de tout comprendre aux subtilités
de la haute disponibilité. Sinon, reprenons plus doucement :
les sessions sont des fichiers écrits SUR le serveur web, c'est à dire sur la machine qui est active. Si elle
tombe en panne et que l'autre s'active à la place, ces fichiers sont perdus... et les personnes connectées se
retrouvent déconnectées. En effet, pour la seconde machine, toutes les personnes dialoguant avec elle sont de
NOUVEAUX clients. Elle va donc leur redemander de s'identifier.
Pour éviter cela, il faut mettre en commun ces fichiers de session, et de manière plus générale
tous les fichiers à même d'être stockés sur une machine donnée (document Word envoyé via un formulaire, etc.).
Ceci peut se faire de plusieurs manières :
- Réplication en temps réel, par exemple avec rsync
- Stockage des données communes sur un serveur de fichier annexe
C'est cette dernière solution qui a été retenue ici, principalement pour introduire l'exemple suivant. Dans la pratique, il conviendra d'étudier les 'pour' et les 'contre' de chaque technique. Voici un rapide résumé non exhaustif des avantages / inconvénients :
| rsync | serveur de fichiers | |
|---|---|---|
| Avantages : |
|
|
| Inconvénients : |
|
|
La solution finale ressemblera donc à ceci :
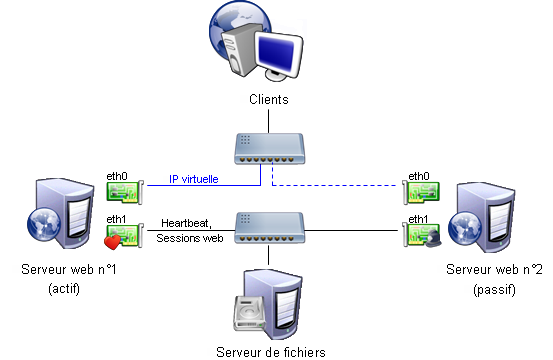
Ici encore, on pourra se passer de la seconde carte réseau et tout faire transiter sur le même commutateur.
Cependant, le trafic généré pour le stockage des sessions, fichiers partagés et les données d'heartbeat
risquent de ralentir un peu le trafic réseau des clients.
Serveur de fichiers
Si vous avez analysé attentivement la solution précédente, vous vous êtes certainement dit : "oui, mais si je
rajoute un serveur de fichier et que c'est lui qui tombe en panne, je fais comment ?". Remarque pertinente.
Il n'y a pas le choix, il faut le mettre EGALEMENT en haute disponibilité. Vous découvrez alors avec horreur
et consternation qu'il va falloir rajouter une machine de plus à votre parc déjà bien rempli par votre serveur
Exchange, vos deux serveurs de relais de messagerie, vos deux serveurs web et votre premier serveur de fichiers.
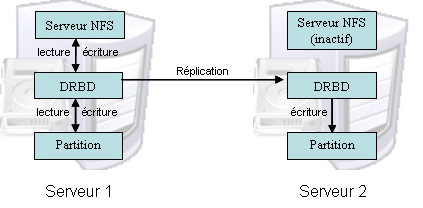
La solution la plus simple pour créer ce type de serveur est d'utiliser DRBD.
C'est un programme qui synchronise en temps réel une partition entre deux machines (une sorte de RAID 1 réseau).
Son fonctionnement est le suivant :
- Il se réserve une partition sur les deux serveurs, qui contiendront les données répliquées.
- Il autorise ensuite un seul des serveurs (celui qui est actif) à recevoir des données.
- Lorsqu'une opération a lieu sur cette partition, il l'intercepte et envoie les blocs du disque dur qui ont été modifiés vers l'autre serveur.
Voici le schéma équivalent :
Sa mise en place est expliquée en détail dans un des tutoriels cités dans les références. L'implémentation physique de cette solution ressemble à s'y méprendre à celle du relais de messagerie :
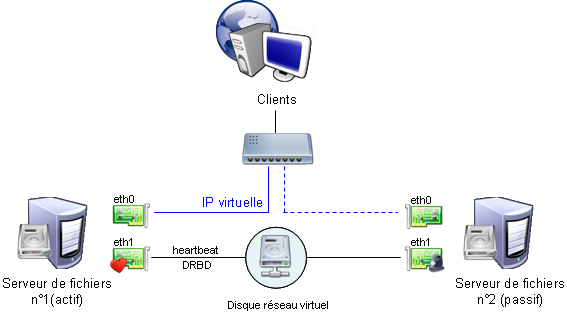
Seule différence notable : le lien 'eth1' sert à envoyer les données de DRBD en plus des données de
contrôle de Heartbeat.
Serveurs SQL
Voici enfin le dernier cas étudié ici et le plus complexe : le cas où plusieurs serveurs actifs sont nécessaires en même temps. Prenons pour cet exemple des bases de données en cluster :
- Plusieurs serveurs SQL en cluster discutent entre eux (on suppose ici qu'ils utilisent un protocole 'propriétaire', comme MySQL Cluster).
- Un gestionnaire va intercepter les requêtes des clients utilisant l'adresse IP virtuelle et les rediriger vers un des serveurs en cluster de son choix.
- Un gestionnaire de secours va écouter le gestionnaire principal et prendre sa place en cas de défaillance.
Le schéma correspondant est alors :
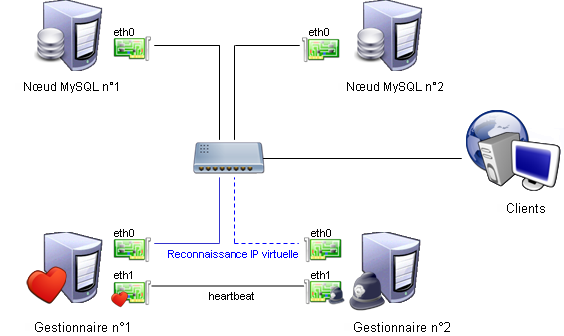
On retrouve un peu la même architecture qu'en services actif/passif, sauf que cette fois-ci les gestionnaires
sont dissociés des machines proposant les services.
Voilà. Vous avez maintenant vu les principaux mécanismes pour migrer un service en haute disponibilité, avec tous
les problèmes cachés qui peuvent en découler. Ces problèmes seront spécifiques à chaque type de service que vous
essaierez de mettre en place. Aussi, prenez le temps de bien analyser la situation avant de commencer à
implémenter une solution !
Si vous êtes toujours accroché, nous allons pouvoir passer à la dernière étape du processus : mettre la main
à la pâte et voir comment configurer les programmes.