HIDS et systèmes Unix
Surveillance des logs
La surveillance des fichiers journaux s'effectue de diverses manières suivant le système choisi. Logcheck, par défaut, s'exécute toutes les heures et après chaque redémarrage. Il analyse les logs (exemple : syslog et auth.log) à la recherche de patterns. Les patterns vérifiés sont configurables et dépendent du niveau de configuration : paranoid, server ou workstation, par ordre de verbosité décroissant.
De la même manière, le moteur d'OSSEC se base sur un fonctionnement par patterns, décrits dans un fichier XML. Dans les règles décrites, il est possible de spécifier de ne lever une alerte que si un pattern a déjà été repéré précédemment, dans un espace temps défini. L'exemple donné dans la documentation d'OSSEC est le suivant :
<rule id="1608" level="13" timeframe="120">
<regex>^sshd[\d+]: fatal: Local: crc32 compensation attack</regex>
<if_matched_regex>^sshd[\d+]: \.+Corrupted check by bytes on</if_matched_regex>
<comment>SSH CRC-32 Compensation attack</comment>
<info>http://www.securityfocus.com/bid/2347/info/</info>
</rule>
L'alerte "SSH CRC-32 Compensation attack" ne sera levée que si le motif défini par l'expression régulière "^sshd[\d+]: fatal: Local: crc32 compensation attack" a été trouvé et que précédemment, dans un temps de temps de 120 secondes, le motif défini par l'expression régulière "^sshd[\d+]: \.+Corrupted check by bytes on" avait été trouvé.
Contrôle d'intégrité des fichiers
Le contrôle d'intégrité, tel que pratiqué par tripwire, samhain et OSSEC, se base sur des fonctions de hachage cryptographiqe (cryptographic hash functions). Une fonction de hachage cryptographique permet, à partir d'une entrée de taille variable (par exemple, un fichier), de produire une chaîne d'octets de taille fixe, dont la longueur dépend de la fonctionutilisée. Elle a de plus les propriétés suivantes :
- Résistante à la pré-image. Etant donné un hash h (le résultat d'une fonction de hachage), il doit être très difficile de trouver une entrée e1 tel que h = hash(e1).
- Résistante à la seconde pré-image. Etant donné une entrée e1, il doit être très difficile de trouver une autre entrée e2 telle que hash(e1) = hash(e2). C'est principalement pour ces deux particularités qu'une fonction de hachage cryptographique est choisie : la modification d'un fichier doit être visible.
- Résistante aux collisions. Il doit être difficile de trouver deux entrées quelconques e1 et e2 telle que hash(e1) = hash(e2). On peut notamment citer les travaux de Joux et de Wang sur MD5 qui ont trouvé des collisions pour MD5. Il devient alors très simple, pour cet algorithme, de générer deux fichiers différents qui ont le même hachage MD5, en se basant sur le principe que : si md5(e1) = md5(e2) alors md5(e1 + q) = md5(e2 + q).
Afin d'éviter d'être dépendant de la sécurité d'une seule fonction de hachage, si l'une des résistances aux pré-images venait à être « cassée », la plupart des HIDS effectuant des contrôles d'intégrité se basent généralement sur plusieurs algorithmes de hachage (notamment CRC32, SHA-1 et MD5).
Il est relativement simple d'implémenter un mécanisme de vérification d'intégrité. Il suffit de vérifier régulièrement une liste pré-définie de fichiers et de s'assurer que leur somme de contrôle correspond à celle dans la base de données. Le principe peut-être démontré de la façon suivante :
dek@corleone:~$ echo -n "Ceci est un exemple" > exemple
dek@corleone:~$ cksum exemple ; md5sum exemple ; sha1sum exemple
85423185 19 exemple
8fecb1c2a8f9bed59a9ef2669116677a exemple
f400e8ac5446fba7102511acb7c04547b6be99ad exemple
dek@corleone:~$ echo " modifié" >> exemple
dek@corleone:~$ cksum exemple ; md5sum exemple ; sha1sum exemple
1939367049 28 exemple
b4ea2482980c7c25f30664659a4dd0d5 exemple
cf63b07b68a2ba58f53cb9bb81a8acdfec87142d exemple
Note: cksum effectue un hash CRC, qui n'est pas une fonction cryptographique. De plus, l'exemple est effectué sur un système GNU/Linux. Sur un système BSD, il faudra remplacer les commandes md5sum et sha1sum par, respectivement, md5 et sha1.
Aussi, la plupart des systèmes vérifient aussi le possesseur du fichier, les permissions, et la date de modification.
Bien évidemment, la base de donnée contenant les hashs ne doit pas être altérée. Une fois celle-ci générée sur un système sain et fonctionnel, elle doit donc être stockée sur un support amovible et de préférence non altérable comme un CD-ROM. La comparaison s'effectuera par la suite sur cette base.
Détection de rootkits
Un rootkit est un ensemble de modifications effectués par un attaquant afin de cacher ses traces. Les rootkits peuvent se situer à plusieurs niveaux : au niveau des binaires (executables et librairies) ou au niveau kernel. Les rootkits de binaire affectent généralement des outils comme ps, ls, kill, top, du, find, netstat etc. ainsi que les librairies, notamment les librairies dynamiques et par exemple, libproc.so. Ces fichiers sont modifiés afin de cacher la présence de fichiers ou de processus appartenant à l'attaquant d'un système. Toutes ces modifications peuvent-être détectées par un contrôle d'intégrité des fichiers pour peu que l'on soit sûr que les composants servant à la détection n'ont pas été modifiés : c'est pourquoi il est utile de stocker les binaires et autres librairies nécessaires à la détection d'une rootkit sur un médium non altérable.
En revanche les rootkits kernel modifient le fonctionnement de celui-ci pour cacher à un niveau supérieur (kernel land) les informations : les fichiers sont cachés au niveau du système de fichier, les processus sont cachés lors de la consultation de la table des processus etc. Ces backdoors sont les plus difficiles à détecter sur un système en fonctionnement en ceci que les applications qui les détectent sont exécutées par le kernel... qui est backdooré.
Originellement, les rootkits kernel fonctionnaient après une modification des sources du kernel et une recompilation (fastidieux) ou, beaucoup plus difficilement, par l'écriture dans des devices comme /dev/kmem. L'avénement des modules noyaux (LKM Loadable Kernel Modules) et leur chargement dynamique a rendu la tâche beaucoup plus aisée aux pirates : il s'agissait alors de développer son propre module modifiant les syscalls (appel système, voir Détection de comportements douteux) et les drivers souhaités pour que toutes les applications userland soient affectées.
Les fonctionnements des détecteurs de rootkits kernel sont généralement à la recherche de patterns connus dans les modules chargés et vérifient aussi que les syscalls n'ont pas été modifiés. Sur un système en fonctionnement, cela peut s'avérer fastidieux : rien ne garantit que ce que l'on exécute effectue bien ce que l'on souhaite et le jeu entre détecteurs et rootkits consiste à penser à ce que l'autre n'a pas prévu.
Exemple : on redéfinit le syscall sys_execve pour que la demande d'exécution du programme foobar donne les privilèges root à l'appelant. La détection d'un tel rootkit est aisée, on peut par exemple demander la liste des modules chargés avec lsmod et s'apercevoir qu'un module douteux est présent, ou encore vérifier les symboles avec /proc/kallsyms. Le code du rootkit peut alors se cacher de la liste des modules et de /proc/kallsyms en se retirant de la liste chaînée des modules chargés. Cependant, l'utilisation de /dev/kmem permettra toujours de s'en apercevoir. Il est alors possible de rediriger les accès à /dev/kmem etc.
Détection de comportement douteux
La détection de comportement douteux consiste à partir d'un constat simple : un programme est conçu pour effectuer un ensemble de tâches définies. Si un processus effectue une autre tâche que celle prévue, il sort de son comportement normal et présente donc un risque pour le système. Il convient donc de surveiller le déroulement d'un processus et de s'assurer qu'il respecte ce pour quoi il a été conçu. Ceci peut s'effectuer de plusieurs manières. Systrace, par exemple, permet de définir une politique de sécurité au niveau des syscalls.
Un syscall est un appel système. C'est une des portes d'entrée entre le user land et le kernel land. Il permet à une application de demander un service au noyau du système d'exploitation. Sur les systèmes dits POSIX (Portable Operating System Interface), c'est à dire les systèmes unifiés autour d'une API définie par l'IEEE (Institution of Electrical Engineers) pour les systèmes Unix. Des appels systèmes courants sont : sys_open, sys_close, sys_fork, sys_execve, sys_kill, sys_read, sys_write etc. Dès qu'une application souhaite accéder à une ressource, par exemple à un fichier sur le système de fichier, elle en demande l'ouverture par le biais de sys_open qui, au niveau kernel, appellera les fonctions correspondantes au système de fichier concerné, allouera un descripteur de fichier et le retournera à l'application.
Systrace permet de restreindre les applications (et en ceci, intègre le fonctionnement d'un IPS), individuellement, à un nombre de syscalls spécifiés. De plus, cette application permet de limiter les paramètres d'un syscall. Par exemple, la commande ping n'a nul besoin d'exécuter /bin/sh. Ainsi, si une faille venait à apparaître dans ping, il serait impossible pour un attaquant de faire exécuter à ping une autre application et encore moins /bin/sh.
De plus, systrace permet de se débarasser des bits sgid et suids en autorisant l'application à tourner avec un privilège donné que pour certains syscalls. Par exemple, ping n'a pas besoin d'être root pendant tout le temps de son exécution : seulement pour pouvoir envoyer un datagramme ICMP. Ainsi, encore une fois, si une faille est découverte dans ping, les autres syscalls ne s'executeront pas en étant privilégiés. Ce fonctionnement permet aussi de s'affranchir des problèmes que l'on peut rencontrer si certaines applications ne se séparent pas assez bien de leurs privilèges. Un exemple de configuration de politique pour le binaire ls donnée sur le site de systrace est le suivant :
Policy: /bin/ls, Emulation: native
native-munmap: permit
[...]
native-stat: permit
native-fsread: filename match "/usr/*" then permit
native-fsread: filename eq "/tmp" then permit
native-fsread: filename eq "/etc" then deny[enotdir]
native-fchdir: permit
native-fstat: permit
native-fcntl: permit
[...]
native-close: permit
native-write: permit
native-exit: permit
Avec une telle politique, il est possible de lister les fichiers dans /usr/*, dans /tmp mais pas ceux sdans /etc. Tout autre tentative, comme lister les fichiers dans /bin, ou /var génèreront un warning.
systrace peut apprendre la politique par défaut d'une application en l'analysant alors qu'elle s'exécute. Ensuite, il est possible d'éditer cette politique et de la modifier selon ses goûts. Notons que l'apprentissage ne sera pas en théorie jamais complet : on se heurte au problème d'incomplètude de Gödel et, plus précisément, au problème de l'arrêt d'une machine de Turing.
Les syscalls par la pratique
Il est possible de constater le fonctionnement d'un programme au niveau des appels systèmes assez aisément grâce à l'outil strace sous GNU/Linux ou truss sur un système BSD. Comme strace fork() d'abord pour créer un nouveau processus et l'attache ensuite avec ptrace et la requête PTRACE_TRACEME, on obtient notamment le fonctionnement du loader d'executables. Exemple :
dek@corleone:~/tmp$ ls
bar dump foo foobar
dek@corleone:~/tmp$ strace ls > /dev/null
> On exécute /usr/bin/ls
> 36 vars indique qu'il y a 36 éléments dans l'environnement
> En effet "env | wc -l" retourne 36
execve("/usr/bin/ls", ["ls"], [/* 36 vars */]) = 0
uname({sys="Linux", node="corleone", ...}) = 0
> brk(0) retourne la fin du segment de données
brk(0) = 0x805a000
> On vérifie que /etc/ld.so.preload existe, pour éventuellement pré-charger une librairie dynamique
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
> On essaye tous les path possibles pour charger la librairie dynamique librt.so.1
open("/usr/X11R6/lib/tls/i686/sse2/librt.so.1", O_RDONLY) = -1 ENOENT (No such file or directory)
stat64("/usr/X11R6/lib/tls/i686/sse2", 0xbfc32e80) = -1 ENOENT (No such file or directory)
[...]
> On essaye tous les path possibles pour charger la librairie dynamique librt.so.1
open("/etc/ld.so.cache", O_RDONLY) = 3
> On ouvre le cache généré par ldconfig à partir de /etc/ld.so.conf pour trouver les librairies dynamiques
> On le map en mémoire et on ferme le fichier
fstat64(3, {st_mode=S_IFREG|0644, st_size=50874, ...}) = 0
mmap2(NULL, 50874, PROT_READ, MAP_PRIVATE, 3, 0) = 0xb7f12000
close(3) = 0
> On ouvre la librairie librt.so.1, on la map en mémoire et on interdit notamment l'écriture sur cette zone
open("/lib/tls/librt.so.1", O_RDONLY) = 3
read(3, "\177ELF\1\1\1\0\0\0\0\0\0\0\0\0\3\0\3\0\1\0\0\0\340\34"..., 512) = 512
fstat64(3, {st_mode=S_IFREG|0755, st_size=34582, ...}) = 0
mmap2(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb7f11000
mmap2(NULL, 29228, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0xb7f09000
mmap2(0xb7f0f000, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x5) = 0xb7f0f000
close(3) = 0
> On fait de même pour la libc
open("/usr/X11R6/lib/libc.so.6", O_RDONLY) = -1 ENOENT (No such file or directory)
open("/lib/tls/libc.so.6", O_RDONLY) = 3
read(3, "\177ELF\1\1\1\0\0\0\0\0\0\0\0\0\3\0\3\0\1\0\0\0\300P\1"..., 512) = 512
fstat64(3, {st_mode=S_IFREG|0755, st_size=1366940, ...}) = 0
mmap2(NULL, 1162428, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0xb7ded000
mprotect(0xb7f02000, 27836, PROT_NONE) = 0
mmap2(0xb7f03000, 16384, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x115) = 0xb7f03000
mmap2(0xb7f07000, 7356, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0xb7f07000
close(3) = 0
> Ainsi que pour la libpthread
open("/usr/X11R6/lib/libpthread.so.0", O_RDONLY) = -1 ENOENT (No such file or directory)
open("/lib/tls/libpthread.so.0", O_RDONLY) = 3
[...]
> On charge les locales
open("/usr/lib/locale/locale-archive", O_RDONLY|O_LARGEFILE) = -1 ENOENT (No such file or directory)
brk(0) = 0x805a000
brk(0x807b000) = 0x807b000
open("/usr/share/locale/locale.alias", O_RDONLY) = 3
fstat64(3, {st_mode=S_IFREG|0644, st_size=2586, ...}) = 0
mmap2(NULL, 131072, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb7dba000
read(3, "# Locale name alias data base.\n#"..., 131072) = 2586
read(3, "", 131072) = 0
close(3) = 0
munmap(0xb7dba000, 131072) = 0
open("/usr/lib/locale/en_US/LC_IDENTIFICATION", O_RDONLY) = 3
fstat64(3, {st_mode=S_IFREG|0644, st_size=378, ...}) = 0
mmap2(NULL, 378, PROT_READ, MAP_PRIVATE, 3, 0) = 0xb7f1e000
close(3) = 0
[...]
> On récupère la taille du terminal (43 lignes, 161 colonnes)
> Le descripteur de fichier est stdout
ioctl(1, SNDCTL_TMR_TIMEBASE or TCGETS, {B38400 opost isig icanon echo ...}) = 0
ioctl(1, TIOCGWINSZ, {ws_row=43, ws_col=161, ws_xpixel=970, ws_ypixel=563}) = 0
> On ouvre le fichier "."
open(".", O_RDONLY|O_NONBLOCK|O_LARGEFILE|O_DIRECTORY) = 3
> On récupère le type de fichier ouvert : un répertoire ainsi que sa taille
fstat64(3, {st_mode=S_IFDIR|0700, st_size=144, ...}) = 0
fcntl64(3, F_SETFD, FD_CLOEXEC) = 0
mmap2(NULL, 135168, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb7d8d000
> On récupère les fichiers contenus dans le répertoire
getdents64(3, /* 6 entries */, 131072) = 152
getdents64(3, /* 0 entries */, 131072) = 0
munmap(0xb7d8d000, 135168) = 0
close(3) = 0
fstat64(1, {st_mode=S_IFCHR|0620, st_rdev=makedev(136, 1), ...}) = 0
mmap2(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb7f14000
> On affiche la liste
write(1, "bar dump foo\tfoobar\n", 22) = 22
munmap(0xb7f14000, 4096) = 0
> On quitte l'application
exit_group(0) = ?
Etude de syscalls par analyse graphique
Il est possible de générer un graph de transition des syscalls par l'intermédiaire de graphviz. Ce graph permettra de manière graphique de comprendre les suites logiques d'un syscall à un autre. Par exemple, supposons une application réseau qui écoute sur le port 2600 (nc -l -p 2600) et qui affiche ce qu'elle reçoit sur stdout. netcat est utilisé pour cet exemple. Le graph résultant sera le suivant :
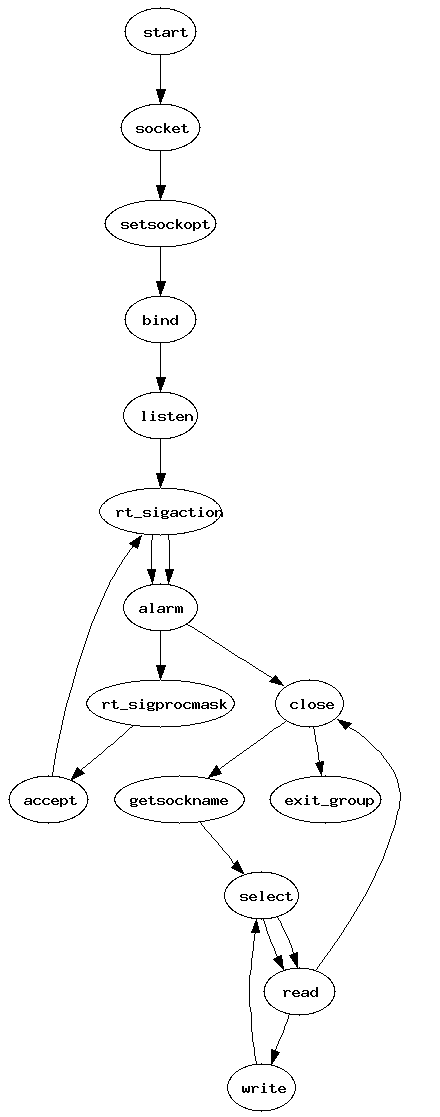
Il est aisé de constater qu'après avoir accept() une nouvelle connexion, le descripteur de socket qui servait à l'écoute est fermé avec close(), puis ce qui a été envoyé est lu et, finalement, affiché sur stdout. En revanche un strace de netcat exécutant un shell lors d'une connexion sur le port 2600 (nc -l -p 2600 -e /bin/sh) est le suivant :
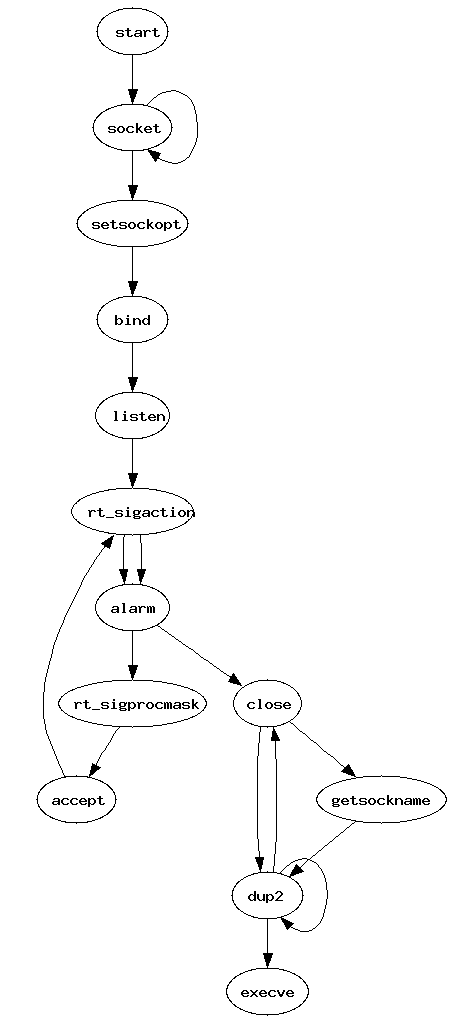
Ici, après la fermeture de la socket d'écoute, les descripteurs de fichier sont dupliqués via dup2 pour que le stdin et le stdout du shell qui vont être exécutés soient le descripteur de la socket. On se rend bien compte que le flow d'exécution a été changé et que si, par l'intermédiaire de systrace on a interdit à netcat d'execve() un autre processus, l'attaque simulée aurait été impossible.
De la même manière une attaque de type buffer overflow aurait changé le flow d'exécution et, vraisemblablement aurait pu être détectée. Cependant cette technique n'est pas parfaite. En effet, il est possible de changer le flow d'exécution de telle manière qu'il corresponde au graphique. De plus, l'approche par le biais de strace n'est pas possible en production : les performances deviennent dramatiques. Pour de meilleures performances il faudra insérer notre code au point d'entrée des syscalls (/usr/src/linux/arch/i386/kernel/entry.S sur linux 2.6.x/x86) ou alors programmer un proxy pour l'ensemble des syscalls.