:: Enseignements :: Master :: M2 :: 2009-2010 :: Traitement Automatique des Langues ::
Le but de ce projet est de développer un programme permettant d'aligner mot à mot des textes déjà alignés par phrases.
![[LOGO]](http://igm.univ-mlv.fr/ens/resources/mlv.png) | Alignement mot à mot |
Le but de ce projet est de développer un programme permettant d'aligner mot à mot des textes déjà alignés par phrases.
Objectifs
Le but de ce projet est de développer un programme permettant d'aligner mot à mot des textes déjà alignés par phrases.
Chaque mot d'un bloc de texte en langue cible sera aligné avec au plus un mot de bloc aligné en langue source, et vice-versa.
Un alignement peut donc être vu comme un tableau où chaque indice correspond à un indice de mot dans le texte cible.
L'élément correspondant sera l'indice du mot aligné en langue source.
Les langues du corpus parallèle de travail sont l'anglais et le français.
Méthode
Pour cela, vous devrez implémenter deux programmes:
- un programme d'apprentissage des différents paramètres de l'aligneur, à partir d'un corpus d'entrainement. Ce corpus se trouve dans un répertoire dont le nom est passé en argument au programme.
- un programme d'alignement qui prend deux fichiers alignés en phrase comme arguments et qui les aligne mot à mot.
Ressources
Pour ce projet, vous disposez d'un corpus parallèle anglais-français aligné en phrases, issu du corpus europarl.
Il se situe dans le répertoire suivant: /home/ens/mconstan/corpus/europarl-light.
Il comporte deux sous-répertoires train et test contenant respectivement un corpus parallèle d'entrainement et un corpus parallèle de test.
Chacun d'eux a un répertoire en (pour l'anglais) et un répertoire fr (pour le français).
Chaque fichier du répertoire en correspond au fichier de même nom dans le répertoire fr (et vice-versa).
Les blocs de textes de chaque ligne des paires de fichiers sont alignés un à un.
Les fichiers sont encodés en utf-8.
Niveau 1
Le premier niveau de ce projet est de construire un aligneur utilisant une des deux heuristiques vues en cours.
On considère un mot comme un simple token-mot.
Indication : la méthode à suivre correspond au sujet de TP sur l'alignement.
Attention : une des deux méthodes est plus complexe à mettre en oeuvre. Ce paramètre sera pris en compte dans l'évaluation du projet.
Indication : la méthode à suivre correspond au sujet de TP sur l'alignement.
Attention : une des deux méthodes est plus complexe à mettre en oeuvre. Ce paramètre sera pris en compte dans l'évaluation du projet.
Niveau 2
Dans ce niveau, la définition d'un mot change.
Un mot peut désormais être un token-mot ou un mot composé.
Cela implique donc un prétraitement avec Unitex de chaque texte traité.
Niveau 3
Il vous est demandé de trouver une petite extension à votre méthode pour améliorer les résultats.
Implémenter votre solution.
Sortie de l'aligneur et rendu graphique
L'aligneur pend deux fichiers textes alignés par phrases en arguments.
Il devra générer un fichier qui, pour chaque ligne des deux textes, indique les alignements.
Il se trouve sous cette forme:
L'alignement aux mots de deux blocs de textes est représenté en trois lignes.
La liste des mots du texte source se trouve sur la première ligne.
Les mots sont séparés par des tabulations.
La liste des mots du texte cible se trouve sur la deuxième ligne.
La troisième ligne contient les différents alignements aussi séparés par des tabulations.
Chaque alignement est un triplet: un indice de mot dans le texte source, un indice de mot dans le texte cible et un score d'alignement.

Rendu graphique de l'alignement :
Pour permettre une meilleure visualisation, nous vous fournissons un script python align2dot.py (qui utilise le module viz à placer dans le même répertoire) qui génère au format dot les alignements trouvés. Ce script prend comme argument le fichier généré par l'aligneur et le répertoire où vous souhaitez placer les fichiers au format dot. Ensuite, à l'aide de la commande dot, il vous sera alors possible de générer un graphe en jpg (par exemple) pour chaque phrase du texte. Par exemple, pour obtenir visualiser sous forme graphique les alignements de la deuxième paire de phrases dans l'exemple, il suffira de taper:
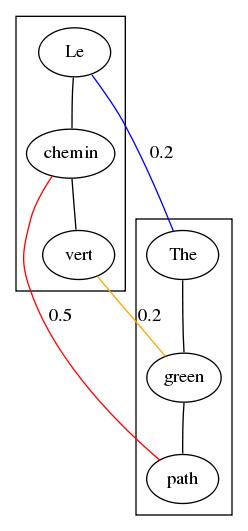
Pour permettre une meilleure visualisation, nous vous fournissons un script python align2dot.py (qui utilise le module viz à placer dans le même répertoire) qui génère au format dot les alignements trouvés. Ce script prend comme argument le fichier généré par l'aligneur et le répertoire où vous souhaitez placer les fichiers au format dot. Ensuite, à l'aide de la commande dot, il vous sera alors possible de générer un graphe en jpg (par exemple) pour chaque phrase du texte. Par exemple, pour obtenir visualiser sous forme graphique les alignements de la deuxième paire de phrases dans l'exemple, il suffira de taper:
dot -Tjpg sentence1.dot -o sentence1.jpegVous obtiendrez alors:
Modalités
Ce travail est personnel.
Vous devrez écrire un rapport de 6 pages maximum.
Il sera envoyé, au format pdf, par email à Matthieu Constant (mconstan [at] univ-mlv point fr) et Eric Laporte (eric.laporte [at] univ-mlv point fr).
L'objet de l'email sera "projet TAL M2 - <votre nom>".
Une présoutenance et une soutenance de 20 min par étudiant seront également organisées.
Pré-soutenance :mardi 17 novembre 2009, à 8h30
Date limite de rendu : mercredi 9 décembre 2009, 23h59
Date de soutenance : jeudi 10 décembre 2009, à 9h
Date limite de rendu : mercredi 9 décembre 2009, 23h59
Date de soutenance : jeudi 10 décembre 2009, à 9h
© Université de Marne-la-Vallée