Dex Format vs Java bytecode
Java Dex Format
Qu'est ce que c'est?
Le format Dex est le format de fichier utilisé pour l'exécution du bytecode Java
sur Android. Ce format est étudié pour s'intégrer au principe d'économie induit
par le système mobile Android.
De ce fait, le format de fichier d'exécution Java dit classique
ne correspondait
plus au besoin du système d'exploitation Android.
Dans la suite de cette page nous verrons la structure interne des fichiers au format Dex.
Structure interne
Le format de fichier Dex inclut des bytecodes spécifiques. De plus, là où les fichiers
d'exécution Java (fichier .class
) sont en nombre identique que les fichiers de sources
(fichier .java
), le fichier d'exécution Dalvik (fichier .dex
), est unique pour
tout un programme Java.
Voici un schéma détaillant les sections dans lesquelles nous pouvons retrouver informations utile à
l'exécution :
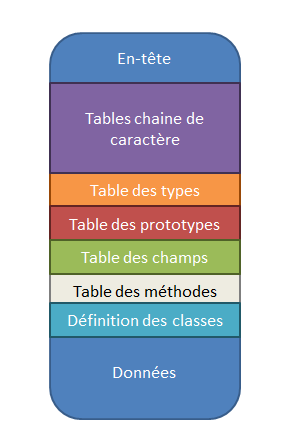
Nous allons donner significations des informations que l'on retrouve dans chaque section
(pour plus de détails voir la
spécification)
d'un fichier .dex
.
L'en-tête
Il s'agit de la partie qui débute chaque fichier au format dex. Celle-ci correspond à une sorte de déclaration des parties suivantes. Elle commence par trois champs qui permettent la détection d'erreur. Ces champs sont :
- Le champ magic : qui est une liste de byte utiliser comme une constante similaire à tous les fichiers au format dex
- Le champ checksum : qui est un checksum réaliser avec l'algorithme adler32 de tout le fichier.
- Le champ signature : qui est un checksum réaliser avec l'algorithme SHA-1 de tout le fichier sauf les champs magic et checksum.
La suite des champs correspondent respectivement à la taille et au décale d'adresse dans le fichier (l'offset) de chaque partie du fichier à partir du début du fichier.
La table de chaîne de caractère (string_ids)
Il s'agit de la partie rassemblant toutes les chaînes de caractères utilisées dans ce fichier correspondant autant aux noms des variables internes qu'aux constantes. Cette partie est constituée d'élément nommé string_id_item. Chaque string_id_item décrit un offset à partir du début du fichier pointant sur la chaîne de caractère voulue dans la partie donnée qui a pour type string_data_item.
La table des types (type_ids)
Il s'agit de la partie rassemblant tous les types utilisés dans ce fichier. Cette partie est constituée
d'élément nommé type_id_item. Chaque élément
du type type_id_item décrit un index de la table de
chaîne de caractère décrivant le type voulu.
Les types reconnus sont les suivants :
| Valeurs | Représentation |
|---|---|
| V | Void |
| Z | boolean |
| B | byte |
| S | short |
| C | char |
| I | int |
| J | long |
| F | float |
| D | double |
| Lnom/pleinement/spécifié | La classe nom.pleinement.spécifié |
| [descriptor] | Tableau de descripteur qualifiant des tableaux de tableau |
La table des prototypes (proto_ids)
Il s'agit de la partie rassemblant tous les prototypes des méthodes utilisés dans ce fichier. Cette partie est constituée d'élément nommé proto_id_item. Chaque proto_id_item est décomposé de trois champs. Le premier champ (nommé shorty_idx) correspond à l'index dans la table de chaîne de caractère décrivant le prototype. Les valeurs que peuvent prendre ce champ sont standardisées. Elles correspondent à la faible représentation d'un prototype. Le deuxième champ (nommé return_type_idx) correspond à un index dans la table des types qui est le type de retour de la méthode. Enfin, le troisième champ (nommé parameters_off) correspond à un offset à partir du début du fichier pointant sur la struture donnée dans laquelle nous retrouverons la liste des paramètres de la méthode. Si la méthode ne possède aucun paramètre, la valeur 0 sera dans ses bytes.
La table des champs (field_ids)
Il s'agit de la partie rassemblant tous les champs utilisés dans ce fichier. Cette partie est constituée d'élément nommé field_id_item. Chaque élément du type field_id_item décrit est décomposé en trois champs. Le premier champ correspond à un l'index dans la table des types et qui doit représenter une classe. Le deuxième champ correspond à un index dans la table des types qui représente le type du champ concerné. Le dernier champ est un index vers la table de chaîne de caractère qui représente le nom du champ.
La table des méthodes (method_ids)
Il s'agit de la partie rassemblant toutes les méthodes utilisées dans ce fichier. Cette partie est constituée d'élément nommé method_id_item. Chaque élément du type method_id_item décrit est décomposé en trois champs. Le premier champ correspond à un l'index dans la table des types et qui représente la classe dans laquelle se trouve la méthode. Le deuxième champ correspond à un index dans la table des prototypes qui représente le prototype de la méthode. Le dernier champ est un index vers la table de chaîne de caractère qui représente le nom de la méthode.
La table des classes (class_defs)
Il s'agit de la partie rassemblant toutes les classes utilisées dans ce fichier. Cette partie est constituée d'élément nommé class_def_item. Chaque élément du type class_def _item décrit dans cette partie décomposé en 8 champs dont voici la signification :
| Nom | Description |
|---|---|
| class_idx | Index dans la table des types qui représente donc la classe concerné |
| access_flags | Descripteur d'accès de la classe (private, final, etc.) |
| superclass_idx | Index dans la table des types qui représente la super classe de cette classe |
| interfaces_off | Offset à partir du début du fichier qui pointe dans la structure donnée et qui correspond à la description de l'interface qu'implémente cette classe. Si cette classe n'implémente aucune interface, cette section aura comme valeur 0 |
| source_file_idx | Index dans la table des chaînes de caractère correspondant au nom du fichier dans lequel se trouvent les sources originales de cette classe. Si cette information est inconnue, la valeur de la constante NO_INDEX se trouvera dans ce champ |
| annotations_off | Offset à partir du début du fichier qui pointe vers la structure donnée et qui correspond à la description de la composition des annotations de cette classe |
| class_data_off | Offset à partir du début du fichier qui pointe vers la structure donnée et qui correspond aux données de cette classe. Si cette classe ne possède pas de donnée, comme pour le cas d'une interface par exemple, cette section sera à 0 |
| static_values_off | Offset à partir du début du fichier qui pointe vers la structure donnée et qui correspond aux champs statiques de cette classe. Si la classe ne possède pas de champ statique, cette section sera à 0. |
Les données (data)
Il s'agit de la partie rassemblant toutes les données déclarées dans ce fichier. Les éléments de cette structure sont les différents types exprimant les déclarations faites dans les déclarations précédentes.
Le Bytecode Dalvik
Les bytecodes Dalvik sont en nombre inférieur vis-à-vis du bytecode standard Java.
(Voir la liste des
bytecodes Dalvik disponible)