 Home Présentation Vocabulaire Problématique Les clusters d'applications comparaison fonctionnement messages exemples + Les clusters de fichiers Conclusion Liens Le Power Point ... Le site web ... mail: cedric.lherm@libertysurf.fr |
Les clusters d'applicationsCette partie a pour but de pésenter les concepts liés aux clusters d'applications. Nous allons tenter de comprendre : - les modes de fonctionnements généraux - les techniques de passages de messages - les limites Nous allons donc traiter les points suivants : - comparaison architecture multiprocesseurs / clusters - mode de fonctionnement - technique d'émission de messages - exemples d'utilisation Comparaison architecture multiprocesseurs / clustersL'avantage des ordinateurs possédant une architecture multiprocesseurs réside dans leur rapidité de temps de calcul.Une application écrite d'une façon non monobloc grâce à l'utilisation de threads autorise le noyau de certains sytèmes, tels que linux, à partager l'exécution de ce programme entre les différents processeurs. Ce type d'exécution permet d'accélérer un calcul d'autant plus que la machine dispose de processeurs. D'un point de vue commercial, cette architecture présente deux problèmes majeurs : - coût - sécurité Le premier point fait référence au prix d'une telle architecture. En effet, un tel ordinateur doit disposer de composants dédiés tel que la carte mère qui doit pouvoir accepter bon nombre de processeurs. Du point de vue sécurité, cette structure ne présente pas de redondance. Si la carte mère connait une défaillance ou l'alimentation, ... tout le système se retrouve stoppé et l'application devient inutilisable. D'un point de vue architecturel, le système de type multiprocesseurs présente un avantage très important. Tous les processeurs de la machine partagent la même mémoire physique. Ceci signifie que les variables manipulées par un processeur sont visible par le second, de même le code source qui est lui aussi plaçé en mémoire centrale est également visible par tous les processeurs. Le schéma suivant résume cette architecture : 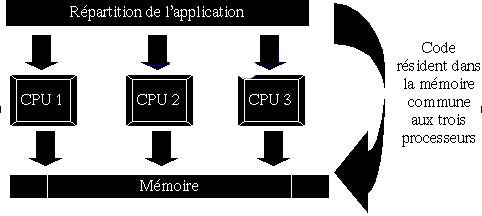
A contrario, il existe la structure en cluster. Les principales différences entre ces deux architectures sont les suivantes : - lenteur de diffusion du code vers les nodes - redondance - coût - performances architecturelles Le premier point présenté ci-dessus fait référence au fait que toutes les machines interconnectées ne partage pas la même mémoire. Ainsi, il est indispensable de diffuser le code à exécuter à chaque node clientes. Cette émission sera vue plus tard, il faut simplement noter que les temps de propagation sur le réseau sont très longs comparés aux temps de propagation sur le bus interne d'un ordinateur. Les clusters utilisent, quant à eux, un méchanisme permettant une redondance importante. Les nodes serveurs utilisent une adresse IP virtuelle négociée en permanence. Dans le cas ou un serveur connaitrait une défaillance, un autre prendrait immédiatemment la relève. Ce méchanisme fonctionne également lorsqu'un serveur connaît une trop grosse charge réseau. Il n'est plus en mesure de répondre donc il perd son adresse virtuelle et un autre serveur moins surchargé prend la relève. D'un point de vue coût, une structure en clusters peut être mise en place à partir de machines standards monoprocesseur (au minimum des Pentiums). L'avantage lié à ces clusters est lié à la mise en place d'une machine virtuelle disposant d'une puissance de calcul démultipliée et d'une capacité en mémoire et disque inégalable. Nous allons maintenant voir comment fonctionne une telle architecture Fonctionnement des clusters d'applicationsAfin de partager la charge processeur d'un calcul, les clusters utilisent un méchanisme de passage de messages. Nous avons vu précédemment que ce type de calcul reposait sur des applications de type client serveur.Il est bien entendu évident que le code a exécuter n'est pas présent sur la node cliente, il est donc primordial de diffuser ces sources vers la node concernée afin que cette dernière recompile ce code en fonction de son architecture (système, processeurs, ...) et l'exécute. Cette diffusion est effectuée grâce à plusieurs librairies de passage de messages permettant de véhiculer le code entre les différentes machines. Celle-ci se nomment (pour les applications sous licences GNU) : - PVM : Parallel Virtual Machine - MPI : Message Passing Interval - AFAPI : Aggregate Function API Ces librairies utilisent des principes théoriques fort simple pour répartir le calcul entre plusieurs node. Les personnes ayant développé les premiers calculs en parallèle se sont tout d'abord posé une question importante : Quelles parties d'un code informatique demandent le plus de temps de calcul ? Après réfléxion, ces personnes en sont arrivées à la conclusion que les temps de calcul importants étaient liés aux boucles. Ainsi les algorithmes utilisés dans ces librairies consistent à répartir l'exécution de ces boucles entre les différentes nodes.Comme nous le savons, les boucles sont des méchanismes permettant de répéter n fois une partie de code. Le but est de répartir ces boucles entre les différentes nodes qui n'effectuent alors que n / nombre de nodes fois cette partie de code. Par exemple, une boucle en langage C est codée de la façon suivante : for (i=0; i<val; i++) { ... } Cette boucle serait alors exécuté val fois sur la machine locale. Dans le cas des clusters, on "casse" cette boucle entre les nodes en effectuant la manipulation suivante (ces manipulation nécessite du code adapté et des appels de fonctions que nous verrons ci-dessous) : for (i=0; i<val; i+=num_node) { ... } Dans le cas du code ci-dessus, nous voyons que la variable i est incrémenté du numéro de node associé à la machine sur laquelle le code s'éxécute. Ce principe permet, en théorie, de diviser le temps de calcul d'autant plus qu'il y a de machine sur le cluster. Une fois le calcul terminé, chaque machine renvoie son résultat au serveur qui effectue la somme de tous les résultats et obtient le résultat final. Ces méthodes s'adaptent bien entendu à des calculs mathématiques bien spécifiques comme des matrices ou des transformées de Fourier par exemple. Nous allons maintenant voir comment cette technique est implémentée au niveau de chaque librairie et qu'elles sont les avantages et inconvénients de chacunes d'entres elles. Le passage de messagesCette partie va nous permettre de mettre en avant les avantages et inconvénients de chacunes des librairies utilisées dans les clusters et de comparer différents exemples d'utilisation.Commençons tout d'abord par la librairie PVM. PVM Parallel Virtual MachineCette librairie est historiquement la plus ancienne du monde GNU/Linux. Elle est sous licence GPL, et offre l'avantage d'être portable. Ce point est particulièrement important car cette fonctionnalité permet entre autre de partager des applications entre des systèmes différents (à conditions que le code puisse être recompilé pour chaque architecture).L'emission de messages entre les différentes nodes s'effectue quant à elle grâce à des communications de type clients / serveur. Elle est implémentée au niveau TCP, ce qui permet à ce type de cluster de fonctionner sur des réseaux hétérogènes : Ethernet, ATM, PPP, ..., ainsi que sur des sites multi plateformes. Vous pouvez trouver un exemple de programme utilisant PVM à l'adresse suivante : exemple PVM. Ce code présente une méthode de calcul du nombre PI grâce à un cluster. Nous allons voir les principales fonctions utilisées : - pvm_mytid(); : creation d'un id pvm - pvm_joingroup(...); : insciption dans un groupe dont le nom est passé en paramètre - pvm_spawn(...) : fonction permettant de répartir le code entre les différentes nodes. Nécessite bon nombre de paramètres tels que le groupe pvm, les arguments passé au programme, ... Cette fonction peut être comparable à la création d'un thread, mais dans le cas d'un cluster, il est déporté sur une machine distante du réseau. - pvm_barrier(...) : contrôle si toutes les nodes demandées sont présentes sur le cluster. Cette fonction attend en paramètre le nom du groupe pvm ainsi que le nombre de nodes attendues. - pvm_reduce(...) : récupère les calculs effectués par les différentes nodes. Cette fonction accepte en paramètre le groupe pvm ainsi que le type des valeurs renvoyées par les nodes. - pvm_barrier(...) : met fin au cluster en précisant le nom de celui-ci et le nombre de participants - pvm_lvgroup(...) : désinscrit la node courante du groupe passé en paramètre. - pvm_exit() : arrête l'exécution du code Comme nous pouvons le voir, l'execution et la mise en place d'un tel code est assez longue à mettre en oeuvre et assez complexe de part le nombre de fonctions et les paramètres transmis. Toutes ces raisons ont motivé la création de la librairie MPI plus convivial et plus simple d'utilisation MPI Message Passing InterfaceCette librairie est identique à la précédente à la différence près qu'elle est beaucoup plus complète. D'une part celle-ci est normée et standardisée ainsi elle demeure compatible avec des systèmes d'exploitation différents. Ensuite, elle rajoute bon nombre de fonctionnalités énumérées ci-dessous :- communications asynchrones - synchronisations entre les groupes gérées par le système - 3ème partie profile : permet d'extraire des informations sur la programmation du cluster à partir du code compilé Ces spécifications sont utilisées dans trois types d'implémentations listées ci-dessous : - LAM : implémente la norme MPI 1.1, elle permet d'exécuter le code généré sur une machine ou un cluster en utilisant une communication de type TCP/IP. - MPICH : cette librairie de haut niveau s'appuie également sur MPI 1.1, elle est portable car elle utilise des niveaux d'abstraction importants. - AFMPI : cette librairie utilise la dernière norme MPI : MPI 2.0. Elle est essentiellement utilisée sur les réseaux locaux ayant un faible taux de latence. Vous pouvez trouver un exemple de programme utilisant MPI à l'adresse suivante : exemple MPI. Ce code présente le même calcul du nombre PI mais avec une librairie MPI. Le code utilisant cette librairies est beaucoup plus simple à mettre en oeuvre que le code utilisant la librairie vue précédemment. Voici les principales fonctions utilisées : - MPI_init(...) : crée le cluster. Nécessite le passage en paramètre des différents arguments du programme. - MPI_Comm_Size(...) MPI_Comm_rank(...) : permet d'initialiser le cluster et d'attendre l'adhésion de chaque node - MPI_Reduce(...) : recupère les calculs effectués par chaque node et attend en paramètre le type de variable de retour la communauté appartenant au cluster, ... - MPI_finalize() : met fin au cluster Nous pouvons voir que la mise en place d'un tel code est beaucoup plus simple qu'avec la librairie précédente. Nous allons maintenant voir une librairie totalement différente. AFAPI Aggregate Function APICette dernière librairie appartenant au monde GNU/Linux est différentes des précédentes pour plusieurs raisons. D'une part, elle travaille d'une façon très rapprochée avec le matériel de façon à obtenir des temps de réponse très courts (proche des ms). Son but est de concurrencer les calculateurs industriels existant sur le marché.Pour ce faire, elle s'appuie sur une librairie bas niveau nommée PAPERS (Purdue's Adapter for Parallel Execution and Rapid Synchronisation). Cette norme a été standardisée ce qui rend AFAPI portable sur différents systèmes. Pour accélérer son exécution, elle utilise des broadcasts Ethernet et outrepasse les appels systèmes en accédant directement au périphérique. Vous pouvez trouver un exemple de programme utilisant AFAPI à l'adresse suivante : exemple AFAPI. Ce code présente le même calcul du nombre PI mais avec une librairie AFAPI. Cette librairie est encore plus simple a utiliser que les deux précédentes, les trois fonctions à utiliser sont décrites ci-dessous : - p_init() : creation du cluster - p_reduce_Add64f(...) : récupération d'un calcul partagé entre les nodes; nécessite de passer en paramètre la variable a récupérer - p_exit() : arrêt et fin du cluster Voyons maintenant quelques applications utilisant les clusters de fichiers. Exemples de clustersNous allons voir les deux principaux systèmes actuels utilisant des technologies de type clusters d'applications.Earth simulator ASCI White
Cet ordinateur virtuel constitue le plus gros cluster au monde. Il permet de simuler l'activité climatique de la Terre grâce à la récupération de nombreuses données venant des satellites et de nombreux points d'observation. Il est entre autre capable de simuler l'impact de pollutions maritimes et environnementales. Enfin, sa dernière utilisation réside dans l'étude des phénomènes terrestres tels que la tectonique des plaques et les tremblements de terre.
Ce cluster est le second plus grand au monde. Sa taille est équivalente à celle de deux terrains de basket côte à côte. Il s'appuie sur des applications développées en langages C/C++ et Fortran. Il est utilisé par l'armée américaine pour effectuer des tests sur ses armes nucléaires : - sécurité des centres de stockages - contrôle du vieillissement Ce cluster constitue un prototype. En 2005, la seconde génération devra être capable de calculer 100 trillions d'instructions par seconde. Nous allons maintenant voir une autre utilisation des clusters à travers les clusters de fichiers.
|
 Problématique
Problématique