:: Enseignements :: Master :: M1 :: 2007-2008 :: Informatique linguistique ::
Le but de ce projet est d'écrire un programme capable de prendre en paramètre une page web, et d'en extraire le texte en identifiant la langue dans laquelle il est écrit. Si le document est composé de plusieurs langues, on souhaite que le programme identifie les différentes langues utilisées.
MÉTHODE A
Étape 1
Calculer à partir du fichier contenant les mots les facteurs autorisés de longueur inférieure ou égale à n.
Étape 2
Par récurrence sur leur longueur m, on construit tous les facteurs interdits minimaux de longueur inférieure ou égale à n.
Pour m=1:
Les facteurs interdits de longueur 1 sont tous les caractères ne figurant pas dans les facteurs autorisés de longueur 1.
Pour m>1:
Pour chaque facteur autorisé u de longueur m-1 et pour chaque facteur autorisé a de longueur 1 :
Si au n’est pas un facteur autorisé de longueur m et ne contient aucun facteur interdit minimal de longueur inférieure à m, alors au est un facteur interdit minimal de longueur m.
MÉTHODE B
Étape 1
Construire à partir du fichier des mots l’arbre A des facteurs autorisés. L’alphabet est constitué par les facteurs autorisés de longueur 1.
Étape 2
Explorer en profondeur l’arbre A. Pour chaque nœud correspondant à un mot u=x1x2...xn, regarder chaque lettre a de l’alphabet : s’il n’y a pas de transition sortant de ce nœud par a (ua n’est pas un facteur autorisé) et si x2...xna appartient à l'arbre A (x2...xna est un facteur autorisé), alors ua est un facteur interdit minimal, puisqu’il est interdit et qu’on ne peut le décomposer qu’en facteurs autorisés.
Exemple:
On veut calculer les facteurs interdits minimaux de longueur maximum 3 sur le texte suivant :
" je pense que tu manges. "
Si on choisit de prendre comme alphabet les lettres mais pas le point ni l’espace, on obtient " a, e, g, j, m, n, p, q, s, t, u ". Avec cet alphabet, on construit l’arbre A suivant :
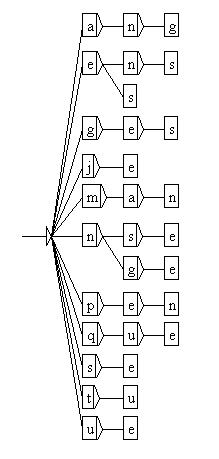
Voici une étape de l’exploration de l’arbre A :
On est au nœud correspondant au mot " pe " et on a parcouru les lettres de l’alphabet jusqu’à " s ".
---French---
Ceci est une page web de test pour le détecteur de langues
---English---
This is a test page for the language detector
![[LOGO]](http://igm.univ-mlv.fr/ens/resources/mlv.png) | Détection de langues dans une page web |
Le but de ce projet est d'écrire un programme capable de prendre en paramètre une page web, et d'en extraire le texte en identifiant la langue dans laquelle il est écrit. Si le document est composé de plusieurs langues, on souhaite que le programme identifie les différentes langues utilisées.
Définitions
On appelle facteur interdit d'une langue toute séquence de caractères n’apparaissant pas dans cette langue.
Exemple: wz et jklm sont deux facteurs interdits du français
On appelle facteur interdit minimal d'une langue tout facteur interdit ne contenant lui-même aucun facteur interdit.
Exemple: wz est minimal mais pas jklm car jk est un facteur un interdit (pour le français)
Reconnaissance de la langue par facteurs interdits
Il existe plusieurs méthodes pour reconnaître la langue d’un texte : regarder l’alphabet
utilisé dans ce texte, consulter des dictionnaires, ... Ces méthodes présentent deux défauts : elles nécessitent
souvent des données sur les langues considérées et/ou fonctionnent mal sur des échantillons de texte très courts.
Pour résoudre ce problème, nous allons formaliser l’intuition qui nous suggère
que stéganographie est un mot plutôt français et schaftbesonders un mot plutôt allemand,
et ce, même si ces deux mots n’existent pas ou sont inconnus du lecteur.
En effet, les facteurs interdits d’une langue rendent bien compte de la morphologie de cette langue. Ainsi,
schaftbesonders ne contiendra vraisemblablement aucun facteur interdit de l’allemand mais plusieurs du
français. On peut donc se faire une bonne idée de la langue d’un texte en mesurant le nombre de facteurs interdits
obtenus pour chacune des langues que l’on souhaite tester.
L’avantage principal de cette méthode est qu’il n’y a pas besoin de connaître une langue pour la traiter,
il suffit d’en avoir un échantillon suffisamment représentatif.
Construction de l’arbre des facteurs interdits minimaux de longueur maximum n d’un langage
On souhaite construire l’arbre des facteurs interdits minimaux de longueur maximum n pour
un langage en supposant que les mots de ce langage sont stockés dans un fichier.
MÉTHODE A
Étape 1
Calculer à partir du fichier contenant les mots les facteurs autorisés de longueur inférieure ou égale à n.
Étape 2
Par récurrence sur leur longueur m, on construit tous les facteurs interdits minimaux de longueur inférieure ou égale à n.
Pour m=1:
Les facteurs interdits de longueur 1 sont tous les caractères ne figurant pas dans les facteurs autorisés de longueur 1.
Pour m>1:
Pour chaque facteur autorisé u de longueur m-1 et pour chaque facteur autorisé a de longueur 1 :
Si au n’est pas un facteur autorisé de longueur m et ne contient aucun facteur interdit minimal de longueur inférieure à m, alors au est un facteur interdit minimal de longueur m.
MÉTHODE B
Étape 1
Construire à partir du fichier des mots l’arbre A des facteurs autorisés. L’alphabet est constitué par les facteurs autorisés de longueur 1.
Étape 2
Explorer en profondeur l’arbre A. Pour chaque nœud correspondant à un mot u=x1x2...xn, regarder chaque lettre a de l’alphabet : s’il n’y a pas de transition sortant de ce nœud par a (ua n’est pas un facteur autorisé) et si x2...xna appartient à l'arbre A (x2...xna est un facteur autorisé), alors ua est un facteur interdit minimal, puisqu’il est interdit et qu’on ne peut le décomposer qu’en facteurs autorisés.
Exemple:
On veut calculer les facteurs interdits minimaux de longueur maximum 3 sur le texte suivant :
" je pense que tu manges. "
Si on choisit de prendre comme alphabet les lettres mais pas le point ni l’espace, on obtient " a, e, g, j, m, n, p, q, s, t, u ". Avec cet alphabet, on construit l’arbre A suivant :
Voici une étape de l’exploration de l’arbre A :
On est au nœud correspondant au mot " pe " et on a parcouru les lettres de l’alphabet jusqu’à " s ".
- " s " est dans l’alphabet et aucune transition par " s " ne sort du nœud : " pes " est candidat pour être un facteur interdit minimal. On vérifie si " es " est dans l’arbre A et comme c’est le cas, on en déduit que " pes " est un facteur interdit minimal. On passe à la lettre suivante.
- " t " est dans l’alphabet et il n’y a pas de transition sortante du nœud par " t ". Cependant, comme " et " n’appartient pas à l’arbre A, on note que " pet " n’est pas un facteur interdit minimal (en effet, il contient " et " qui est lui-même un facteur interdit). On passe à la lettre suivante.
- etc...
Sujet
Le but de ce projet sera d’implémenter un programme permettant d'analyser une page web passée en paramètre
et d'afficher son contenu en UTF8 sur la sortie standard en indiquant quelles sont les langues utilisées.
Votre programme devra être capable de détecter automatiquement l'encodage de la page web. Voici un exemple de ce que
pourrait être la sortie de votre programme sur une page de test:
---French---
Ceci est une page web de test pour le détecteur de langues
---English---
This is a test page for the language detector
À vous de décider quelle partie d'une page web doit être affichée ou non. Je vous conseille de tester votre programme
sur des pages complexes, comme par exemples les news de Yahoo.
Vous travaillerez sur les 7 langues suivantes : français, anglais, italien, allemand, espagnol, portugais et grec.
Vous utiliserez pour cela la méthode des facteurs interdits. D'autres critères peuvent être pris en compte
mais de façon secondaire (statistiques sur les mots courants et les lettres courantes,
caractères spéciaux non pris en compte dans l'alphabet général, format de la date...).
Travail demandé
Vous devrez présenter 2 programmes : l’un permettant de construire l’ensemble des facteurs interdits pour
une liste de mots donnée, l’autre permettant de traiter une page web passée en paramètre.
Vous devrez établir des corpus de référence pour les 7 langues (journaux, thèses...) afin de construire vos ensembles de facteurs
interdits. Vous discuterez dans le rapport de la validité de vos corpus (qualité de l’orthographe, représentativité, ...).
L’environnement de développement ainsi que le langage de programmation sont libres. Toutefois, vous pouvez réutiliser librement
le code d'Unitex 2.0 beta, qui contient des facilités pour lire et écrire des fichiers dans divers encodages.
Le format de données que vous utiliserez pour représenter vos facteurs interdits est libre. ATTENTION : votre programme de construction
de l’ensemble des facteurs interdits doit pouvoir fonctionner indépendamment de la langue. La construction doit être efficace,
elle sera testée en soutenance.
Vous rédigerez un rapport consignant et discutant tous vos choix algorithmiques et linguistiques.
Vous respecterez la charte des projets.
La date de rendu sera fixée ultérieurement.
© Université de Marne-la-Vallée